As the AI landscape has expanded to include
dozens of distinct large language models (LLMs), debates over which model provides the "best" answers for any given prompt have also proliferated (Ars has even
delved into these
kinds of debates a few times in recent months). For those looking for a more rigorous way of comparing various models, the folks over at the Large Model Systems Organization (LMSys) have
set up Chatbot Arena, a platform for generating Elo-style rankings for LLMs based on a crowdsourced blind-testing website.
Chatbot Arena users can enter any prompt they can think of into the site's form to see side-by-side responses from two randomly selected models. The identity of each model is initially hidden, and results are voided if the model reveals its identity in the response itself.
The user then gets to pick which model provided what they judge to be the "better" result, with additional options for a "tie" or "both are bad." Only after providing a pairwise ranking does the user get to see which models they were judging, though a separate "side-by-side" section of the site lets users pick two specific models to compare (without the ability to contribute a vote on the result).
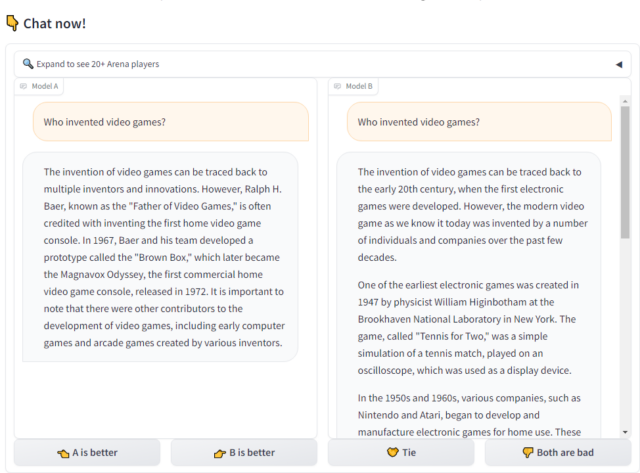
A blind test on our old favorite "Who invented video games?" prompt. Note that Model B goes on
for much longer if you scroll (and mistakenly says Nintendo and Atari were making video games
in the '60s)
Since its public launch back in May, LMSys says it has gathered over 130,000 blind pairwise ratings across 45 different models (as of early December). Those numbers seem poised to increase quickly after a recent positive review from OpenAI's Andrej Karpathy that has already led to what LMSys describes as "a super stress test" for its servers.
Chatbot Arena's thousands of pairwise ratings are crunched through a Bradley-Terry model, which uses random sampling to generate an Elo-style rating estimating which model is most likely to win in direct competition against any other. Interested parties can also dig into the raw data of tens of thousands of human prompt/response ratings for themselves or examine more detailed statistics, such as direct pairwise win rates between models and confidence interval ranges for those Elo estimates.
And the winner is...
Chatbot Arena's latest public leaderboard update shows a few proprietary models easily beating out a wide range of open-source alternatives. OpenAI's ChatGPT-4 Turbo leads the pack by a wide margin, with only an older GPT-4 model ("0314," which was discontinued in June) coming anywhere close on the ratings scale. But even months-old, defunct versions of GPT-3.5 Turbo outrank the highest-rated open-source models available in Chatbot Arena's testbed.
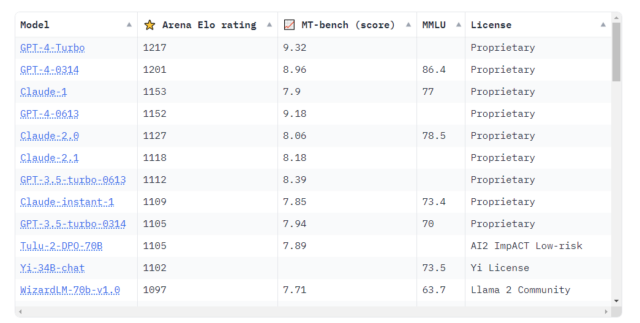
Chatbot Arena's current leaderboards show GPT-4 Turbo and other proprietary models are still the best in class.
Chatbot Arena
Anthropic's proprietary Claude models also feature highly in Chatbot Arena's top rankings. Oddly enough, though, the site's blind human testing tends to rank the older Claude-1 slightly higher than the subsequent releases of Claude-2.0 and Claude-2.1.
Among the tested non-proprietary models, the Llama-based Tulu 2 and 01.ai's Yi get rankings that are comparable to some older GPT-3.5 implementations. Past that, there's a slow but steady decline until you get to models like Dolly and StableLM at the bottom of the pack (amid older versions of many models that have more recent, higher-ranking updates on Chatbot Arena's charts).
This kind of ranking system has its flaws, of course. Humans may be ill-equipped to accurately rank chatbot responses that sound plausible but hide harmful
hallucinations of incorrect information, for instance. Chatbot Arena users may also naturally gravitate towards certain types of prompts that favor certain types of models; LMSys's own
LLM-assisted analysis of user-submitted Arena prompts finds requests for role-playing professional personas, writing stories, and "exploring ethical dilemmas and societal norms" among the most popular categories.
To balance out these potential human biases, LMSys has also developed a completely automated ranking system called LLM Judge, which uses LLM models themselves to rank the quality of responses from other LLMs into an "MT-Bench" score. Those rankings are also compared to a standardized MMLU evaluation, which ranks models on a variety of common tasks.
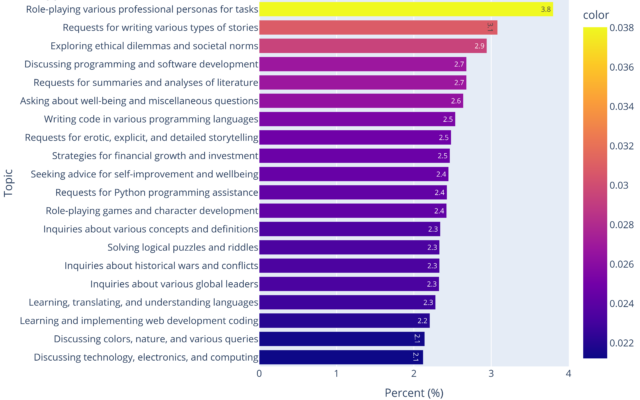
The most common types of prompts users submit to Chatbot Arena's system.
LMSys
LMSys's academic paper on the subject finds that "strong LLM judges like GPT-4 can match both controlled and crowdsourced human preferences well, achieving over 80% agreement, the same level of agreement between humans." From those results, the organization suggests that having LLMs rank other LLMs provides "a scalable and explainable way to approximate human preferences, which are otherwise very expensive to obtain."
Indeed, comparing the different ranking methods on Chatbot Arena's leaderboards finds broadly similar standings. There are some differences, though; MT-Bench ranks UC Berkeley's Starling model as better than some versions of ChatGPT and Claude, while the MMLU tests rank the Yi model alongside the best proprietary models.
While LMSys promises real-time leaderboard updates will be coming soon, the current leaderboards only reflect models added last month. More recently, LMSys revealed in a social media post that the new "mixture of experts" Mixtral model has shown strong (but not proprietary-level) results in early blind trials. We can't wait to see how models like Google's Gemini or even Elon Musk's Grok fare in future direct competition.

3175x175(CURRENT).thumb.jpg.b05acc060982b36f5891ba728e6d953c.jpg)
Recommended Comments
There are no comments to display.
Join the conversation
You can post now and register later. If you have an account, sign in now to post with your account.
Note: Your post will require moderator approval before it will be visible.