

The Hyena code is able to handle amounts of data that make GPT-style technology run out of memory and fail.
For all the fervor over the chatbot AI program known as ChatGPT, from OpenAI, and its successor technology, GPT-4, the programs are, at the end of they day, just software applications. And like all applications, they have technical limitations that can make their performance sub-optimal.
In a paper published in March, artificial intelligence (AI) scientists at Stanford University and Canada's MILA institute for AI proposed a technology that could be far more efficient than GPT-4 -- or anything like it -- at gobbling vast amounts of data and transforming it into an answer.
Known as Hyena, the technology is able to achieve equivalent accuracy on benchmark tests, such as question answering, while using a fraction of the computing power. In some instances, the Hyena code is able to handle amounts of text that make GPT-style technology simply run out of memory and fail.
"Our promising results at the sub-billion parameter scale suggest that attention may not be all we need," write the authors. That remark refers to the title of a landmark AI report of 2017, 'Attention is all you need'. In that paper, Google scientist Ashish Vaswani and colleagues introduced the world to Google's Transformer AI program. The transformer became the basis for every one of the recent large language models.
But the Transformer has a big flaw. It uses something called "attention," where the computer program takes the information in one group of symbols, such as words, and moves that information to a new group of symbols, such as the answer you see from ChatGPT, which is the output.
That attention operation -- the essential tool of all large language programs, including ChatGPT and GPT-4 -- has "quadratic" computational complexity (Wiki "time complexity" of computing). That complexity means the amount of time it takes for ChatGPT to produce an answer increases as the square of the amount of data it is fed as input.
At some point, if there is too much data -- too many words in the prompt, or too many strings of conversations over hours and hours of chatting with the program -- then either the program gets bogged down providing an answer, or it must be given more and more GPU chips to run faster and faster, leading to a surge in computing requirements.
In the new paper, 'Hyena Hierarchy: Towards Larger Convolutional Language Models', posted on the arXiv pre-print server, lead author Michael Poli of Stanford and his colleagues propose to replace the Transformer's attention function with something sub-quadratic, namely Hyena.
The authors don't explain the name, but one can imagine several reasons for a "Hyena" program. Hyenas are animals that live in Africa that can hunt for miles and miles. In a sense, a very powerful language model could be like a hyena, which is picking over carrion for miles and miles to find something useful.
But the authors are really concerned with "hierarchy", as the title suggests, and families of hyenas have a strict hierarchy by which members of a local hyena clan have varying levels of rank that establish dominance. In some analogous fashion, the Hyena program applies a bunch of very simple operations, as you'll see, over and over again, so that they combine to form a kind of hierarchy of data processing. It's that combination element that gives the program its Hyena name.
The paper's contributing authors include luminaries of the AI world, such as Yoshua Bengio, MILA's scientific director, who is a recipient of a 2019 Turing Award, computing's equivalent of the Nobel Prize. Bengio is widely credited with developing the attention mechanism long before Vaswani and team adapted it for the Transformer.
Also among the authors is Stanford University computer science associate professor Christopher Ré, who has helped in recent years to advance the notion of AI as "software 2.0".
To find a sub-quadratic alternative to attention, Poli and team set about studying how the attention mechanism is doing what it does, to see if that work could be done more efficiently.
A recent practice in AI science, known as mechanistic interpretability, is yielding insights about what is going on deep inside a neural network, inside the computational "circuits" of attention. You can think of it as taking apart software the way you would take apart a clock or a PC to see its parts and figure out how it operates.
One work cited by Poli and team is a set of experiments by researcher Nelson Elhage of AI startup Anthropic. Those experiments take apart the Transformer programs to see what attention is doing.
In essence, what Elhage and team found is that attention functions at its most basic level by very simple computer operations, such as copying a word from recent input and pasting it into the output.
For example, if one starts to type into a large language model program such as ChatGPT a sentence from Harry Potter and the Sorcerer's Stone, such as "Mr. Dursley was the director of a firm called Grunnings…", just typing "D-u-r-s", the start of the name, might be enough to prompt the program to complete the name "Dursley" because it has seen the name in a prior sentence of Sorcerer's Stone. The system is able to copy from memory the record of the characters "l-e-y" to autocomplete the sentence.
However, the attention operation runs into the quadratic complexity problem as the amount of words grows and grows. More words require more of what are known as "weights" or parameters, to run the attention operation.
As the authors write: "The Transformer block is a powerful tool for sequence modeling, but it is not without its limitations. One of the most notable is the computational cost, which grows rapidly as the length of the input sequence increases."
While the technical details of ChatGPT and GPT-4 haven't been disclosed by OpenAI, it is believed they may have a trillion or more such parameters. Running these parameters requires more GPU chips from Nvidia, thus driving up the compute cost.
To reduce that quadratic compute cost, Poli and team replace the attention operation with what's called a "convolution", which is one of the oldest operations in AI programs, refined back in the 1980s. A convolution is just a filter that can pick out items in data, be it the pixels in a digital photo or the words in a sentence.
Poli and team do a kind of mash-up: they take work done by Stanford researcher Daniel Y. Fu and team to apply convolutional filters to sequences of words, and they combine that with work by scholar David Romero and colleagues at the Vrije Universiteit Amsterdam that lets the program change filter size on the fly. That ability to flexibly adapt cuts down on the number of costly parameters, or, weights, the program needs to have.
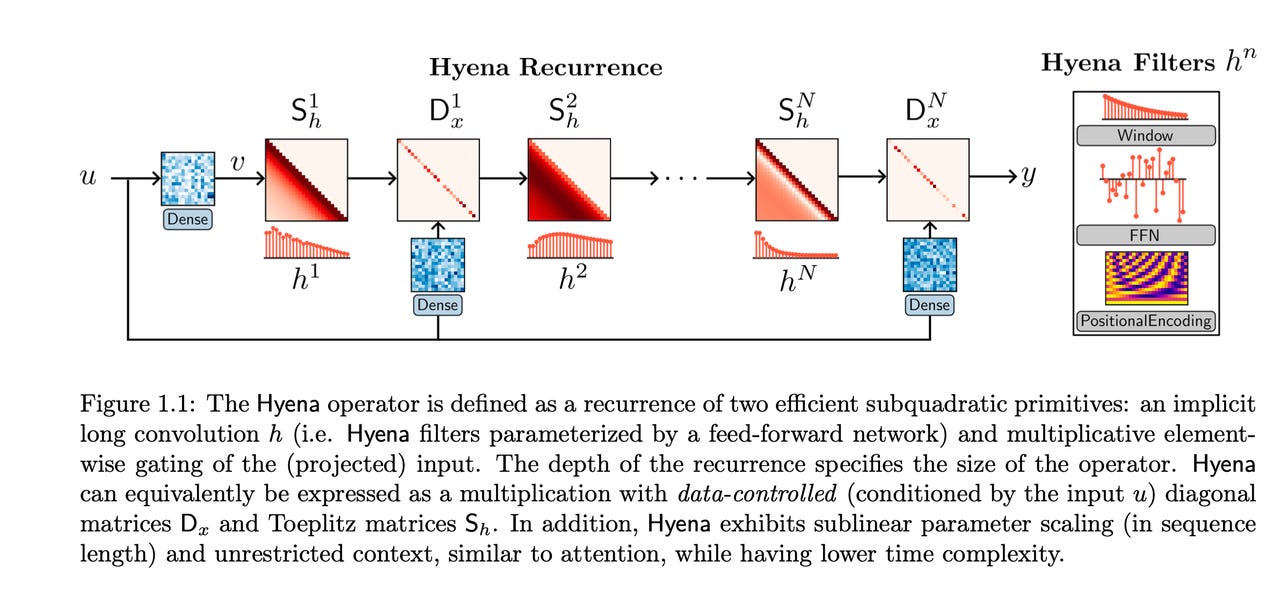
Hyena is a combination of filters that build upon one another without incurring the vast increase in neural network parameters.
Source: Poli et al.
The result of the mash-up is that a convolution can be applied to an unlimited amount of text without requiring more and more parameters in order to copy more and more data. It's an "attention-free" approach, as the authors put it.
"Hyena operators are able to significantly shrink the quality gap with attention at scale," Poli and team write, "reaching similar perplexity and downstream performance with a smaller computational budge." Perplexity is a technical term referring to how sophisticated the answer is that is generated by a program such as ChatGPT.
To demonstrate the ability of Hyena, the authors test the program in a series of benchmark tasks that show how good a new language program is at a variety of AI tasks.
One test is The Pile, an 825-gigabyte collection of texts put together in 2020 by Eleuther.ai, a non-profit AI research outfit. The texts are gathered from "high-quality" sources such as PubMed, arXiv, GitHub, the US Patent Office, and others, so that the sources have a more rigorous form than just Reddit discussions, for example.
The key challenge for the program was to produce the next word when given a bunch of new sentences as input. The Hyena program was able to achieve an equivalent score as OpenAI's original GPT program from 2018, with 20% fewer computing operations -- "the first attention-free, convolution architecture to match GPT quality" with fewer operations, the researchers write.
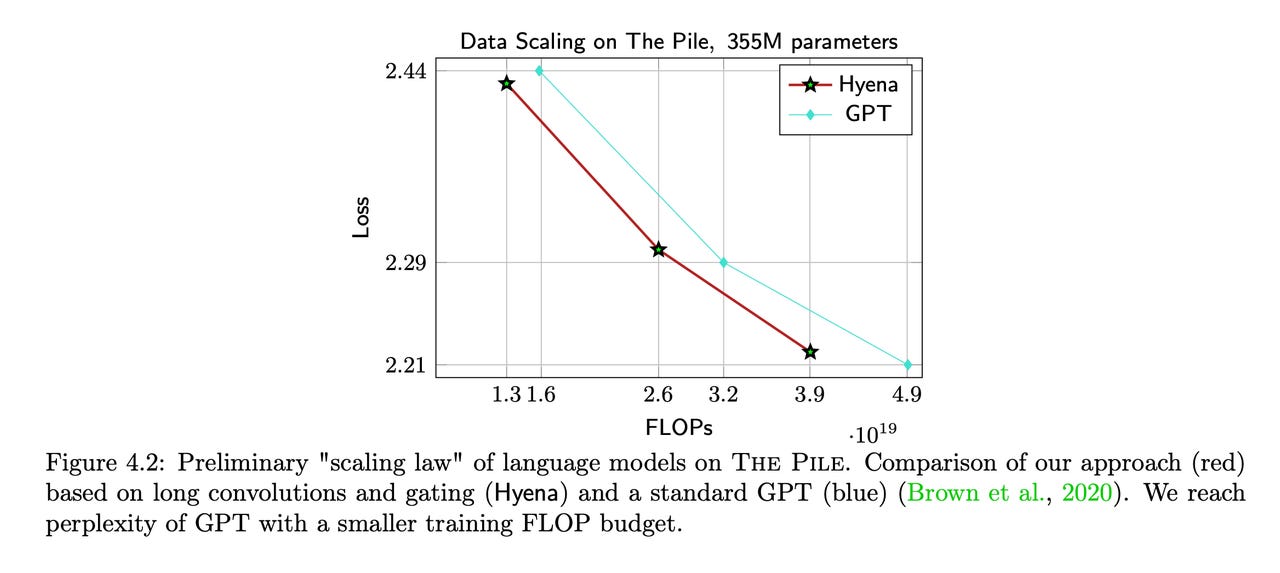
Hyena was able to match OpenAI's original GPT program with 20% fewer computing operations.
Source: Poli et al.
Next, the authors tested the program on reasoning tasks known as SuperGLUE, introduced in 2019 by scholars at New York University, Facebook AI Research, Google's DeepMind unit, and the University of Washington.
For example, when given the sentence, "My body cast a shadow over the grass", and two alternatives for the cause, "the sun was rising" or "the grass was cut", and asked to pick one or the other, the program should generate "the sun was rising" as the appropriate output.
In multiple tasks, the Hyena program achieved scores at or near those of a version of GPT while being trained on less than half the amount of training data.
Even more interesting is what happened when the authors turned up the length of phrases used as input: more words equaled better improvement in performance. At 2,048 "tokens", which you can think of as words, Hyena needs less time to complete a language task than the attention approach.
At 64,000 tokens, the authors relate, "Hyena speed-ups reach 100x" -- a one-hundred-fold performance improvement.
Poli and team argue that they have not merely tried a different approach with Hyena, they have "broken the quadratic barrier", causing a qualitative change in how hard it is for a program to compute results.
They suggest there are also potentially significant shifts in quality further down the road: "Breaking the quadratic barrier is a key step towards new possibilities for deep learning, such as using entire textbooks as context, generating long-form music or processing gigapixel scale images," they write.
The ability for the Hyena to use a filter that stretches more efficiently over thousands and thousands of words, the authors write, means there can be practically no limit to the "context" of a query to a language program. It could, in effect, recall elements of texts or of previous conversations far removed from the current thread of conversation -- just like the hyenas hunting for miles.
"Hyena operators have unbounded context," they write. "Namely, they are not artificially restricted by e.g., locality, and can learn long-range dependencies between any of the elements of [input]."
Moreover, as well as words, the program can be applied to data of different modalities, such as images and perhaps video and sounds.
It's important to note that the Hyena program shown in the paper is small in size compared to GPT-4 or even GPT-3. While GPT-3 has 175 billion parameters, or weights, the largest version of Hyena has only 1.3 billion parameters. Hence, it remains to be seen how well Hyena will do in a full head-to-head comparison with GPT-3 or 4.
But, if the efficiency achieved holds across larger versions of the Hyena program, it could be a new paradigm that's as prevalent as attention has been during the past decade.
As Poli and team conclude: "Simpler sub-quadratic designs such as Hyena, informed by a set of simple guiding principles and evaluation on mechanistic interpretability benchmarks, may form the basis for efficient large models."
- alf9872000, Kaos and Mutton
-
 3
3
Recommended Comments
There are no comments to display.
Join the conversation
You can post now and register later. If you have an account, sign in now to post with your account.
Note: Your post will require moderator approval before it will be visible.