

A new class of incredibly powerful AI models has made recent breakthroughs possible.
Progress in AI systems often feels cyclical. Every few years, computers can suddenly do something they’ve never been able to do before. “Behold!” the AI true believers proclaim, “the age of artificial general intelligence is at hand!” “Nonsense!” the skeptics say. “Remember self-driving cars?”
The truth usually lies somewhere in between.
We’re in another cycle, this time with generative AI. Media headlines are dominated by news about AI art, but there’s also unprecedented progress in many widely disparate fields. Everything from videos to biology, programming, writing, translation, and more is seeing AI progress at the same incredible pace.
Why is all this happening now?
You may be familiar with the latest happenings in the world of AI. You’ve seen the prize-winning artwork, heard the interviews between dead people, and read about the protein-folding breakthroughs. But these new AI systems aren’t just producing cool demos in research labs. They’re quickly being turned into practical tools and real commercial products that anyone can use.
There’s a reason all of this has come at once. The breakthroughs are all underpinned by a new class of AI models that are more flexible and powerful than anything that has come before. Because they were first used for language tasks like answering questions and writing essays, they’re often known as large language models (LLMs). OpenAI’s GPT3, Google’s BERT, and so on are all LLMs.
But these models are extremely flexible and adaptable. The same mathematical structures have been so useful in computer vision, biology, and more that some researchers have taken to calling them "foundation models" to better articulate their role in modern AI.
Where did these foundation models came from, and how have they broken out beyond language to drive so much of what we see in AI today?
The foundation of foundation models
There’s a holy trinity in machine learning: models, data, and compute. Models are algorithms that take inputs and produce outputs. Data refers to the examples the algorithms are trained on. To learn something, there must be enough data with enough richness that the algorithms can produce useful output. Models must be flexible enough to capture the complexity in the data. And finally, there has to be enough computing power to run the algorithms.
The first modern AI revolution took place with deep learning in 2012, when solving computer vision problems with convolutional neural networks (CNNs) took off. CNNs are similar in structure to the brain's visual cortex. They’ve been around since the 1990s but weren’t yet practical due to their intense computing power requirements.
In 2006, though, Nvidia released CUDA, a programming language that allowed for the use of GPUs as general-purpose supercomputers. In 2009, Stanford AI researchers introduced Imagenet, a collection of labeled images used to train computer vision algorithms. In 2012, AlexNet combined CNNs trained on GPUs with Imagenet data to create the best visual classifier the world had ever seen. Deep learning and AI exploded from there.
CNNs, the ImageNet data set, and GPUs were a magic combination that unlocked tremendous progress in computer vision. 2012 set off a boom of excitement around deep learning and spawned whole industries, like those involved in autonomous driving. But we quickly learned there were limits to that generation of deep learning. CNNs were great for vision, but other areas didn’t have their model breakthrough. One huge gap was in natural language processing (NLP)—i.e., getting computers to understand and work with normal human language rather than code.
The problem of understanding and working with language is fundamentally different from that of working with images. Processing language requires working with sequences of words, where order matters. A cat is a cat no matter where it is in an image, but there’s a big difference between “this reader is learning about AI” and “AI is learning about this reader.”
Until recently, researchers relied on models like recurrent neural networks (RNNs) and long short-term memory (LSTM) to process and analyze data in time. These models were effective at recognizing short sequences, like spoken words from short phrases, but they struggled to handle longer sentences and paragraphs. The memory of these models was just not sophisticated enough to capture the complexity and richness of ideas and concepts that arise when sentences are combined into paragraphs and essays. They were great for simple Siri- and Alexa-style voice assistants but not for much else.
Getting the right training data was another challenge. ImageNet was a collection of one hundred thousand labeled images that required significant human effort to generate, mostly by grad students and Amazon Mechanical Turk workers. And ImageNet was actually inspired by and modeled on an older project called WordNet, which tried to create a labeled data set for English vocabulary. While there is no shortage of text on the Internet, creating a meaningful data set to teach a computer to work with human language beyond individual words is incredibly time-consuming. And the labels you create for one application on the same data might not apply to another task.

Enlarge / Example entry in WordNet. Takes a lot of human work to put together!
{kind=link}
You want to be able to do two things. First, you want to train on unlabeled data, meaning text that didn't require a human to mark down details about what it is. You also want to work with truly massive amounts of text and data, taking advantage of the breakthroughs in GPUs and parallel computing in the same way that convolutional network models did. At that point, you can go beyond the sentence-level processing that the RNN and LSTM models were limited to.
In other words, the big breakthrough in computer vision was data and compute catching up to a model that had already existed. AI in natural language was waiting for a new model that could take advantage of the compute and data that already existed.
Translation is all you need
The big breakthrough was a model from Google called "the transformer." The researchers at Google were working on a very specific natural language problem: translation. Translation is tricky; word order obviously matters, but it changes in different languages.
For example, in Japanese, verbs come after the objects they act on. In English, senpai notices you; in Japanese, senpai you notices. And, of course, French is why the International Association Football Federation is FIFA and not IAFF.
An AI model that can learn and work with this kind of problem needs to handle order in a very flexible way. The old models—LSTMs and RNNs—had word order implicitly built into the models. Processing an input sequence of words meant feeding them into the model in order. A model knew what word went first because that’s the word it saw first. Transformers instead handled sequence order numerically, with every word assigned a number. This is called "positional encoding." So to the model, the sentence “I love AI; I wish AI loved me” looks something like (I 1) (love 2) (AI 3) (; 4) (I 5) (wish 6) (AI 7) (loved ") (me 9).
(me 9).
Using positional encoding was the first breakthrough. The second was something called “multi-headed attention.” When it comes to spitting out a sequence of output words after being fed a sequence of input words, the model isn’t limited to just following the strict order of input. Instead, it’s designed so that it can look ahead or back at the input sequence (attention) and at different parts of the input sequence (multi-headed) and figure out what's most relevant to the output.
The transformer model effectively took the problem of translation from a vector representation of words—taking in words in sequence and spitting out words one after another—and made it more like a matrix representation, where the model can look at the entire sequence of the input and determine what's relevant to which part of the output.

Enlarge / An example of how transformers approach translation.
{kind=link}
Transformers were a breakthrough for translation, but they were also exactly the right model for solving many language problems.
They were perfect for working with GPUs because they could process big chunks of words in parallel instead of one at a time. Moreover, the transformer is a model that takes in one ordered sequence of symbols—in this case, words (technically fragments of words, called "tokens")—and then spits out another ordered sequence: words in another language.
And translation doesn’t require complicated labeling of the data. You simply give the computer input text in one language and output text in another. You can even train the model to fill in the blanks to guess what comes next if it's fed a particular sequence of text. This lets the model learn all kinds of patterns without requiring explicit labeling.
Of course, you don’t have to have English as the input and Japanese as the output. You can also translate between English and English! Think about many of the common language AI tasks, like summarizing a long essay into a few short paragraphs, reading a customer’s review of a product and deciding if it was positive or negative, or even something as complex as taking a story prompt and turning it into a compelling essay. These problems can all be structured as translating one chunk of English to another.
The big breakthrough in language models, in other words, was discovering an amazing model for translation and then figuring out how to turn general language tasks into translation problems.
So now we have an AI model that lets us do two critical things. First, we can train by fill-in-the-blanks, which means we don’t have to label all the training data. We can also take entire passages of text—whole books, even—and run them in the model.
We don’t have to tell the computer which lines of text are about Harry Potter and which are about Hermione. We don’t have to explain that Harry is a boy and Hermione is a girl and define boy and girl. We just need to randomly blank out strings like “Harry” and “Hermione” and “he” and “she,” train the computer to fill in the blanks, and in the process of correcting it, the AI will learn not just what text references which character but how to match nouns and subjects in general. And because we can run the data in GPUs, we can start scaling up the models to much larger sizes than before and work with bigger passages of text.
We finally have the model breakthrough that lets us take advantage of the vast amount of unstructured text data on the Internet and all the GPUs we have. OpenAI pushed this approach with GPT2 and then GPT3. GPT stands for "generative pre-trained transformer." The "generative" part is obvious—the models are designed to spit out new words in response to inputs of words. And "pre-trained" means they're trained using this fill-in-the-blank method on massive amounts of text.
In 2019, OpenAI released GPT2. It could generate surprisingly realistic human-like text in entire paragraphs, and they were internally consistent in a way that computer-generated text had never been before. GPT2 was kind of a mad-libs machine. By carefully feeding it sequences of text, called prompts, you could get it to output related sequences of text. It was good, and while the sequences looked like they had internal consistency, the system broke down quickly as the text got longer. And the prompts were a bit like entering search queries in the Alta Vista days—they weren't very flexible.
The biggest breakthrough came in the jump from GPT2 to GPT3 in 2020. GPT2 had about 1.5 billion parameters, which would easily fit in the memory of a consumer graphics card. GPT3 was 100 times bigger, with 175 billion parameters in its largest manifestation. GPT3 was much better than GPT2. It can write entire essays that are internally consistent and almost indistinguishable from human writing.
But there was also a surprise. The OpenAI researchers discovered that in making the models bigger, they didn’t just get better at producing text. The models could learn entirely new behaviors simply by being shown new training data. In particular, the researchers discovered that GPT3 could be trained to follow instructions in plain English without having to explicitly design the model that way.
Instead of training specific, individual models to summarize a paragraph or rewrite text in a specific style, you can use GPT-3 to do so simply by typing a request. You can type “summarize the following paragraph” into GPT3, and it will comply. You can tell it, “Rewrite this paragraph in the style of Ernest Hemingway,” and it will take a long, wordy block of text and strip it down to its essence.
So instead of creating single-purpose language tools, GPT3 is a multi-purpose language tool that can be easily used in many ways by many people without requiring them to learn programming languages or other computer tools. And just as importantly, the ability to learn commands is emergent and not explicitly designed for in the code. The model was shaped by training, and this opens the door to many more applications.
All of this is exciting enough, but the transformer models soon spread to other disciplines beyond language.
Breaking out beyond language: Dall-E, Stable Diffusion, and more
As recently as 2014, XKCD, the sage of all things technical, published this comic:

Less than a decade later, we’ve gone from computers not knowing how to recognize a bird to... well, this:

{kind=link}
How did we get here so quickly?
We already touched upon the starting point—ImageNet, AlexNet, GPUs, and the deep learning revolution. This combination of models, data, and compute gave us an incredible set of tools to work with images.
Computer vision before deep learning was a slog. Think for a moment about how you, as a person, might recognize a face. The whole is made up of the parts; your mind looks for shapes that look like eyes and a mouth and determines how combinations of those shapes fit together in the pattern of a face.
Computer vision research used to be a manual effort of trying to replicate this process. Researchers would toil away looking for the right building blocks and patterns (called “features”) and then try to figure out how to combine them into patterns. My favorite example of this is the Viola-Jones face detector, which worked by recognizing that faces tend to fall into a pattern of a bright forehead and nose in a T-shape, with two dark areas under them.
Deep learning started to change all of this. Instead of researchers manually creating and working with image features by hand, the AI models would learn the features themselves—and also how those features combine into objects like faces and cars and animals. To draw an analogy to language, it’s as if the models were learning a “language” of vision; the “vocabulary” of lines, shapes, and patterns were the basic building blocks, and they were combined higher into the network with rules that served as a “grammar.” But with vast amounts of data, the deep learning models were better than any human researcher.
This was immensely powerful because it gave computers a scalable way to learn rules over images. But it wasn’t yet enough. These models were going in one direction—they could learn to map pixels to categories of objects to drop them into buckets and say, “these pixels show a cat; these pixels show a dog”—but they couldn’t go in the other direction. They were like a tourist who memorizes some stock phrases and vocabulary but doesn't really understand how to translate between the two languages.
You can probably see where we’re going.
Transformers were invented as translators, going from one language to another. You can translate from English to French, English to English, pig latin to English, etc. But really, languages are just ordered sequences of symbols, and translation is simply mapping from one set of ordered sequences to another. Transformers are general-purpose tools for figuring out the rules in one language and then mapping them to another. So if you can figure out how to represent something in a similar way as to a language, you can train transformer models to translate between them.
This is exactly what happened with images. Remember how deep learning figures out representations of the “language” of images? A deep learning model can learn what’s called a "latent space" representation of images. The model learns to extract important features from the images and compresses them into a lower-dimensional representation, called a latent space or latent representation.
A latent representation takes all the possible images at a given resolution and reduces them to a much lower dimension. You can think of it like the model learning an immensely large set of basic shapes, lines, and patterns—and then rules for how to put them together coherently into objects. If you’re familiar with how compression algorithms like JPEG work, it’s like learning a codebook for representing images.
Latent spaces are so named because they function as a coordinate grid that represents aspects of images. For example, representing a car that looks like a face means moving to a point in the latent space that's high on the “looks like a car” axis and also “looks like a face” axis. Effectively, drawing an image (or working with images in general) just means moving about in this space. And mathematically, representing coordinates in a space simply means providing a sequence of numbers. So we have now turned creating or working with images into the problem of creating a sequence… and we know how to do that. In fact, if we imagine each “axis” of the latent space as a symbol or word, we’ve turned "drawing a picture" into something that looks like "writing a sentence."

{kind=link}
We now have a language of images to work with and a tool (the transformer) that lets us do translation. All that’s missing is a set of data to act as a Rosetta stone. And of course, the Internet is full of labeled images—alt text acts as a guide to what's in an image.
OpenAI was able to scrape the Internet to build a massive data set that can be used to translate between the world of images and text. With that, the models, data, and compute came together to translate images into text, and Dall-E was born.
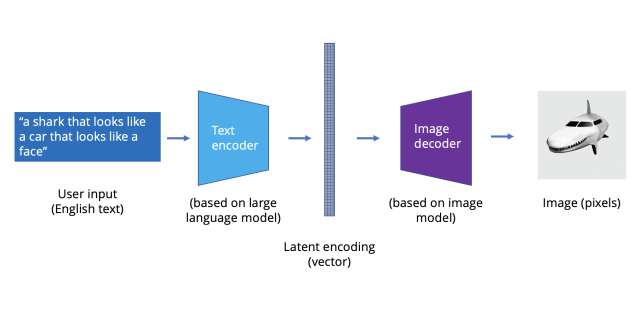
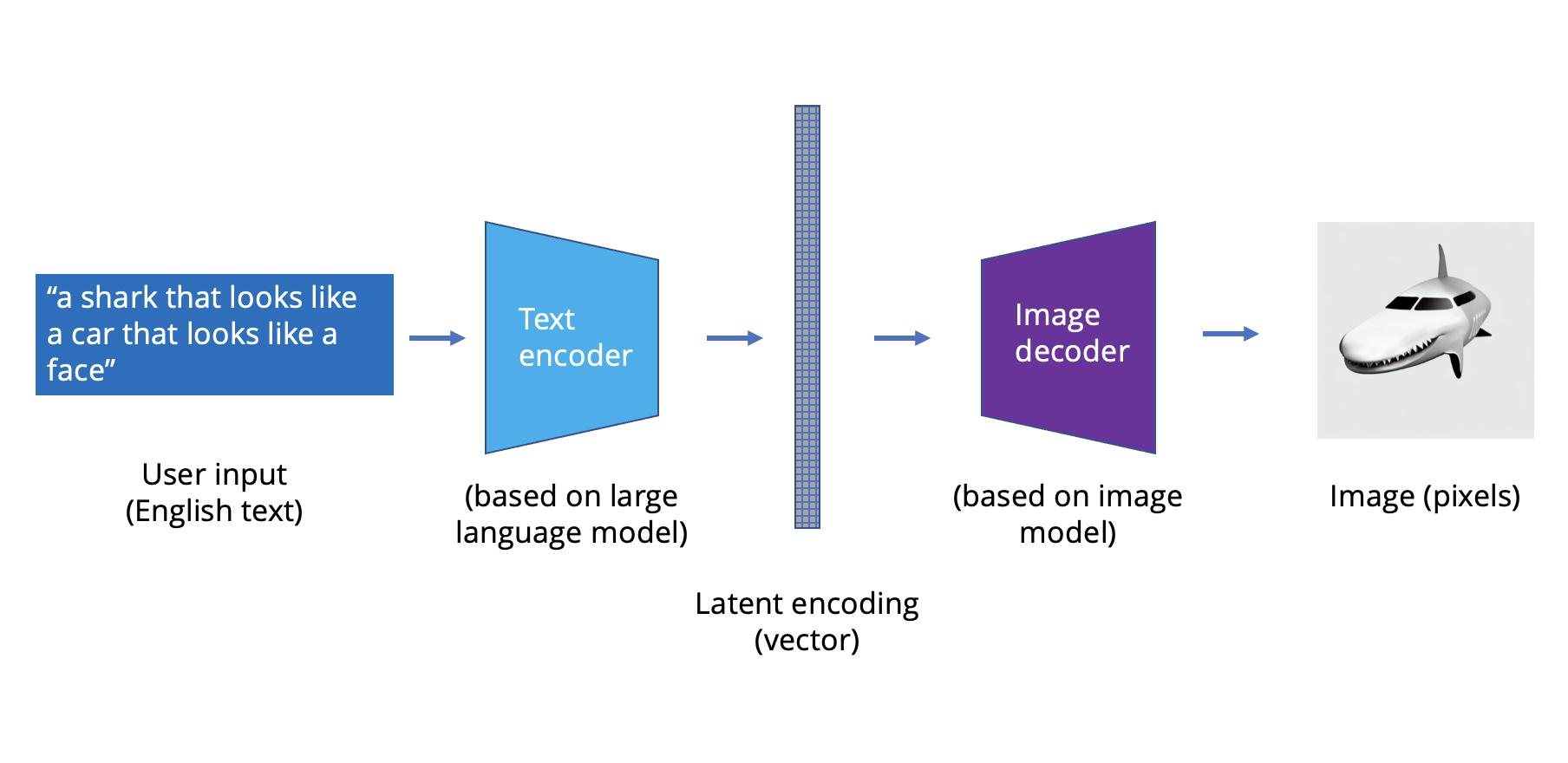{kind=link}
Dall-E is actually a combination of a few different AI models. A transformer translates between that latent representation language and English, taking English phrases and creating “pictures” in the latent space. A latent representation model then translates between that lower-dimensional “language” in the latent space and actual images. Finally, there’s a model called CLIP that goes in the opposite direction; it takes images and ranks them according to how close they are to the English phrase.
The latest image models like Stable Diffusion use a process called latent diffusion. Instead of directly generating the latent representation, a text prompt is used to incrementally modify initial images. The idea is simple: If you take an image and add noise to it, it will eventually become a noisy blur. However, if you start with a noisy blur, you can “subtract” noise from it to get an image back. You must “denoise” smartly—that is, in a way that moves you closer to a desired image.
In this case, instead of a transformer generating pictures, you have a transformer model that takes latent encodings of an image and a text string and modifies the image so it better matches the text. After running a few dozen iterations, you can go from a noisy blur to a sharp AI-generated picture.
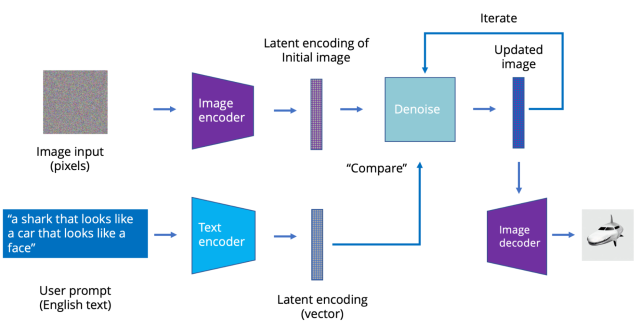
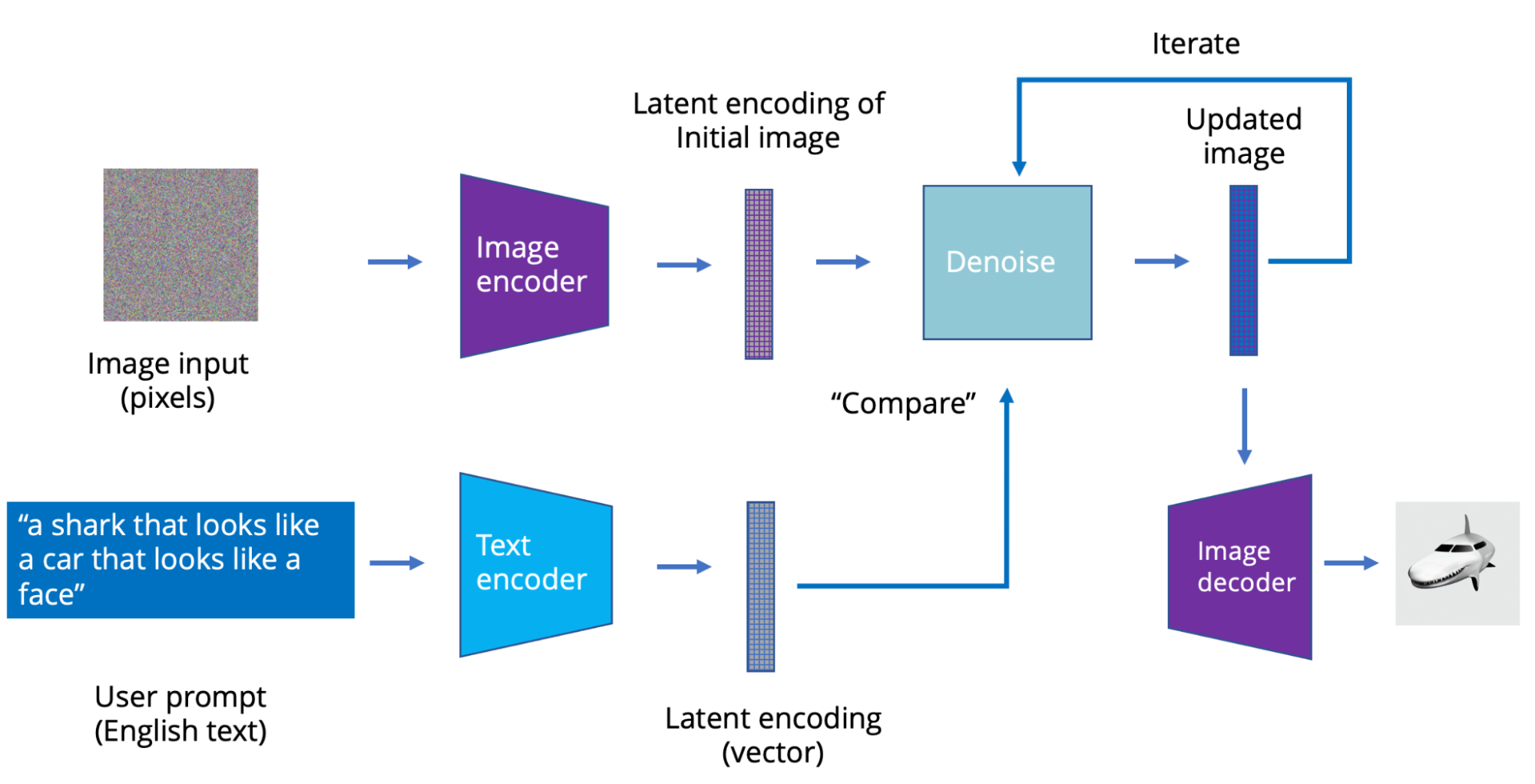{kind=link}
But you don’t have to start with a noisy blur. You can start with another picture, and the transformer will simply adjust from this image toward something it thinks better matches the text prompt. This is how you can have an AI model that takes rough, basic sketches and turns them into photorealistic images.

{kind=link}
To sum up, the breakthrough with generative image models is a combination of two AI advances. First, there's deep learning's ability to learn a “language” for representing images via latent representations. Second, models can use the “translation” ability of transformers via a foundation model to shift between the world of text and the world of images (via that latent representation).
This is a powerful technique that goes far beyond images. As long as there's a way to represent something with a structure that looks a bit like a language, together with the data sets to train on, transformers can learn the rules and then translate between languages. Github’s Copilot has learned to translate between English and various programming languages, and Google’s Alphafold can translate between the language of DNA and protein sequences. Other companies and researchers are working on things like training AIs to generate automations to do simple tasks on a computer, like creating a spreadsheet. Each of these are just ordered sequences.
Generate, evaluate, iterate
These AI models are incredibly powerful and flexible, and it’s useful to talk a bit more broadly about their properties. Namely, data dependence, unpredictability, emergent behaviors, and universality.
If you’ve taken away anything from the above, you know that training AI is dependent on data. Text and images are plentiful, which is why image models like Stable Diffusion and Google’s Imagen were able to follow quickly after Dall-E. Stability.ai is connected to and linked to several open source AI efforts, most notably Eulethera and LAION. Eleuthera created a massive data set of text called "The Pile," and LAION created the LAION-5B set of 5 billion images with corresponding text labels. This data set let other researchers quickly catch up to OpenAI’s efforts in both text and images.
This means AI tools will have different impacts depending on the domain and what kinds of data are available. For example, in robotics, there is not yet an equivalent to ImageNet or LAION to train robot motion planning models with. In fact, there aren’t even good, universally shared formats for data sharing in 3D motion, shapes, and touch—it’s like we're in a world not just before LAION-5B but before JPEG.
Or see drug discovery, where biotech companies are training AIs that can design new drugs. But these new drugs are often exploring new areas of biology—for example, proteins that are unlike naturally evolved samples. AI design has to move hand in hand with huge amounts of physical experiments in labs because the data needed to feed these models just doesn’t exist yet.
Another consideration is that these AI models are fundamentally stochastic. They’re trained using a technique called gradient descent. The training algorithm compares the training data to the output of the AI model and calculates a “direction” to move closer to the right answer. There’s no explicit concept of a right or wrong answer—just how close it is to being correct.
The basic workflow of these models is this: generate, evaluate, iterate. As anyone who’s played with making AI art knows, you typically have to create many examples to get something you like. When working with these AI models, you have to remember that they’re slot machines, not calculators. Every time you ask a question and pull the arm, you get an answer that could be marvelous… or not. The challenge is that the failures can be extremely unpredictable.
The power of these models is shaped by how easy it is to check the answers they give. For example, GPT-3 has pretty good mathematical ability. It’s not just able to do simple arithmetic; it can also interpret word problems at a middle school level or higher. I asked chatGPT to solve a simple math problem, which it did well:

{kind=link}
And when I extended it to bigger numbers, it kept up:
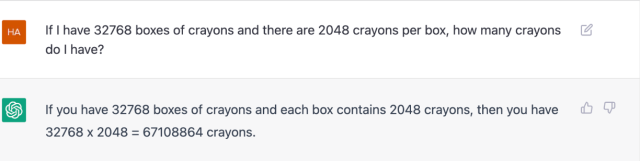
{kind=link}
But it hasn’t actually learned multiplication, just a simulation of it. If I have N boxes with X crayons per box, and N * X = Y, then I have Y crayons. But if I have X boxes with N crayons per box, any kid will tell you that I still have Y crayons!
Let’s see what chatGPT thinks:

{kind=link}
This answer is actually better than it would have been in the past—a previous version of GPT3 would just confidently declare a totally incorrect answer:

{kind=link}
At least now it knows it can’t answer! I chose this example because it’s easy for us to see how wrong the answer is. But what about more complicated domains? While it’s easy to look at a picture that an AI generates and decide if it’s good or bad on a screen, an AI-designed drug candidate has to be synthesized and tested in the real world. This doesn’t mean “AIs are bad and unreliable”; it means that when working with these AIs, this unpredictability has to be kept in mind and designed for.
Indeed, this unpredictability can be good. Remember, many of the capabilities these new models are showing are emergent, so they aren’t necessarily being formally programmed. GPT2 was basically a word-association machine. But when OpenAI made GPT3 a hundred times bigger, researchers discovered it could be trained to explicitly answer questions like “when did dinosaurs go extinct?” without having to be explicitly designed to answer Q&As. The same thing holds true for its ability to obey commands—there's a huge amount of headroom in terms of pushing these models to be even more capable.
And these models are (almost) universal. The fact that they can be used to tie language into different domains—or map directly between different domains—makes them flexible and easy to use in a way that AI models haven’t been before. It’s been very easy to take a trained model and stretch it to many different use cases, and that ease of use is playing out now by bringing these models closer to everyday use.
Startups are popping up to provide AI-powered writing tools, with some finding great commercial success. Large swaths of computational biology research are being overtaken by Alphafold-like models. Programming assistants are going from glorified auto-complete tools to something that can help developers quickly flesh out code from a simple spec. The previous big AI breakthroughs, whether in self-driving cars or playing games, mostly stayed in the province of labs. But anyone can use the writing apps using GPT3 or download Stable Diffusion.
Ubiquity is a big deal. Today, we don’t think of the printing press or the spreadsheet and word processor as being particularly exciting technologies. But by spreading the power of creating information widely, they changed the world—for the better in many cases, but sometimes for the worse. These new AI models have the potential to be just as impactful because of the uses people will put them to.
Predictions are hard. Perhaps the only thing we can say is that these AI tools will continue to get more powerful, easier to use, and cheaper. We’re in the early stages of a revolution that could be as profound as Moore’s Law, and I’m both excited and terrified about what's yet to come.
Haomiao Huang is an investor at Kleiner Perkins, where he leads early-stage investments in hardtech and enterprise software. Previously, he founded the smart home security startup Kuna, built self-driving cars during his undergraduate years at Caltech and, as part of his Ph.D. research at Stanford, pioneered the aerodynamics and control of multi-rotor UAVs.
- Karlston
-
 1
1
Recommended Comments
There are no comments to display.
Join the conversation
You can post now and register later. If you have an account, sign in now to post with your account.
Note: Your post will require moderator approval before it will be visible.