
3175x175(CURRENT).thumb.jpg.b05acc060982b36f5891ba728e6d953c.jpg)
Now, new research from Anthropic offers a new window into what's going on inside the Claude LLM's "black box." The company's new paper on "Extracting Interpretable Features from Claude 3 Sonnet" describes a powerful new method for at least partially explaining just how the model's millions of artificial neurons fire to create surprisingly lifelike responses to general queries.
Opening the hood
When analyzing an LLM, it's trivial to see which specific artificial neurons are activated in response to any particular query. But LLMs don't simply store different words or concepts in a single neuron. Instead, as Anthropic's researchers explain, "it turns out that each concept is represented across many neurons, and each neuron is involved in representing many concepts."
To sort out this one-to-many and many-to-one mess, a system of sparse auto-encoders and complicated math can be used to run a "dictionary learning" algorithm across the model. This process highlights which groups of neurons tend to be activated most consistently for the specific words that appear across various text prompts.

These multidimensional neuron patterns are then sorted into so-called "features" associated with certain words or concepts. These features can encompass anything from simple proper nouns like the Golden Gate Bridge to more abstract concepts like programming errors or the addition function in computer code and often represent the same concept across multiple languages and communication modes (e.g., text and images).
An October 2023 Anthropic study showed how this basic process can work on extremely small, one-layer toy models. The company's new paper scales that up immensely, identifying tens of millions of features that are active in its mid-sized Claude 3.0 Sonnet model. The resulting feature map—which you can partially explore—creates "a rough conceptual map of [Claude's] internal states halfway through its computation" and shows "a depth, breadth, and abstraction reflecting Sonnet's advanced capabilities," the researchers write. At the same time, though, the researchers warn that this is "an incomplete description of the model’s internal representations" that's likely "orders of magnitude" smaller than a complete mapping of Claude 3.
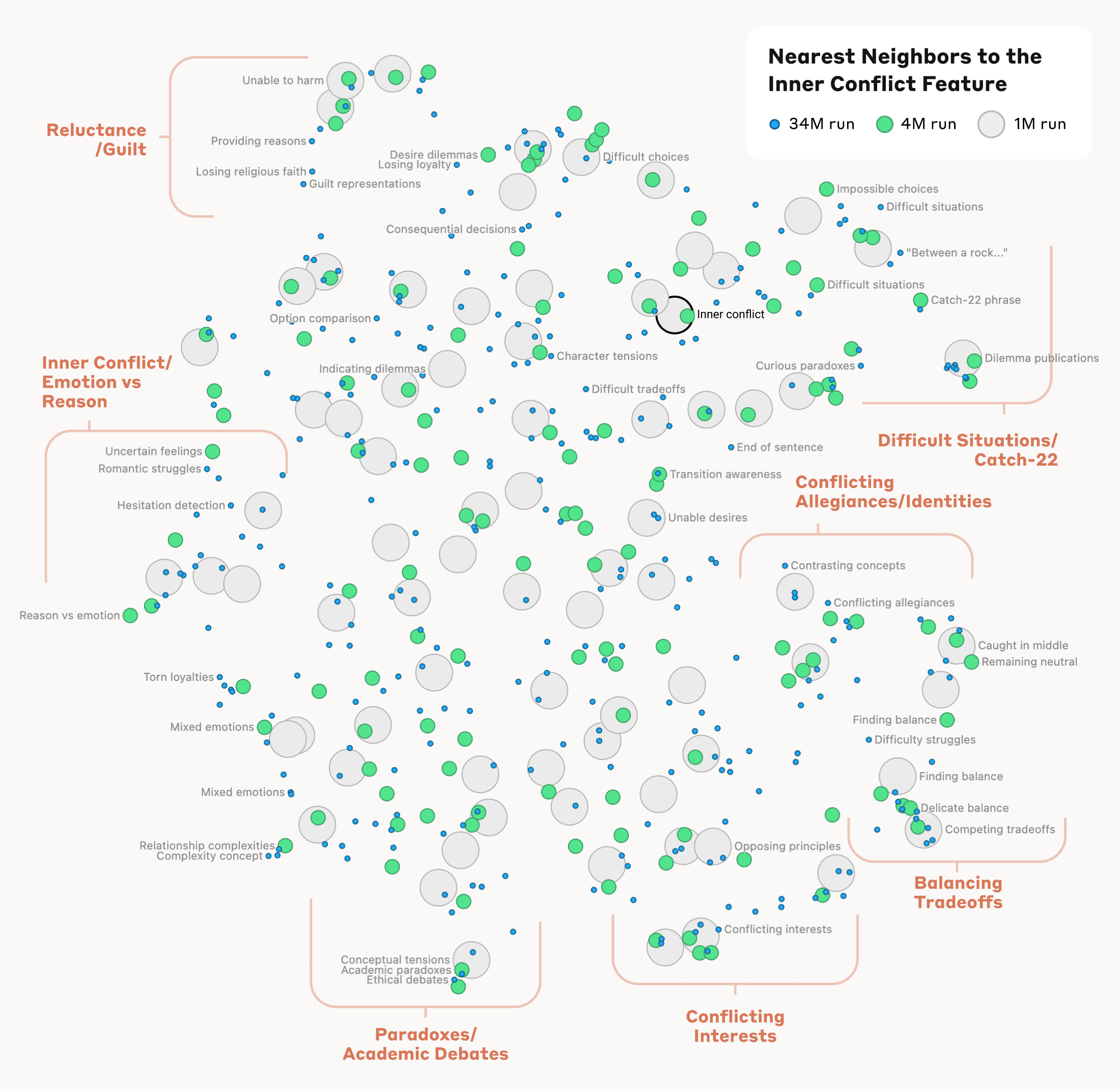
Even at a surface level, browsing through this feature map helps show how Claude links certain keywords, phrases, and concepts into something approximating knowledge. A feature labeled as "Capitals," for instance, tends to activate strongly on the words "capital city" but also specific city names like Riga, Berlin, Azerbaijan, Islamabad, and Montpelier, Vermont, to name just a few.
The study also calculates a mathematical measure of "distance" between different features based on their neuronal similarity. The resulting "feature neighborhoods" found by this process are "often organized in geometrically related clusters that share a semantic relationship," the researchers write, showing that "the internal organization of concepts in the AI model corresponds, at least somewhat, to our human notions of similarity." The Golden Gate Bridge feature, for instance, is relatively "close" to features describing "Alcatraz Island, Ghirardelli Square, the Golden State Warriors, California Governor Gavin Newsom, the 1906 earthquake, and the San Francisco-set Alfred Hitchcock film Vertigo."
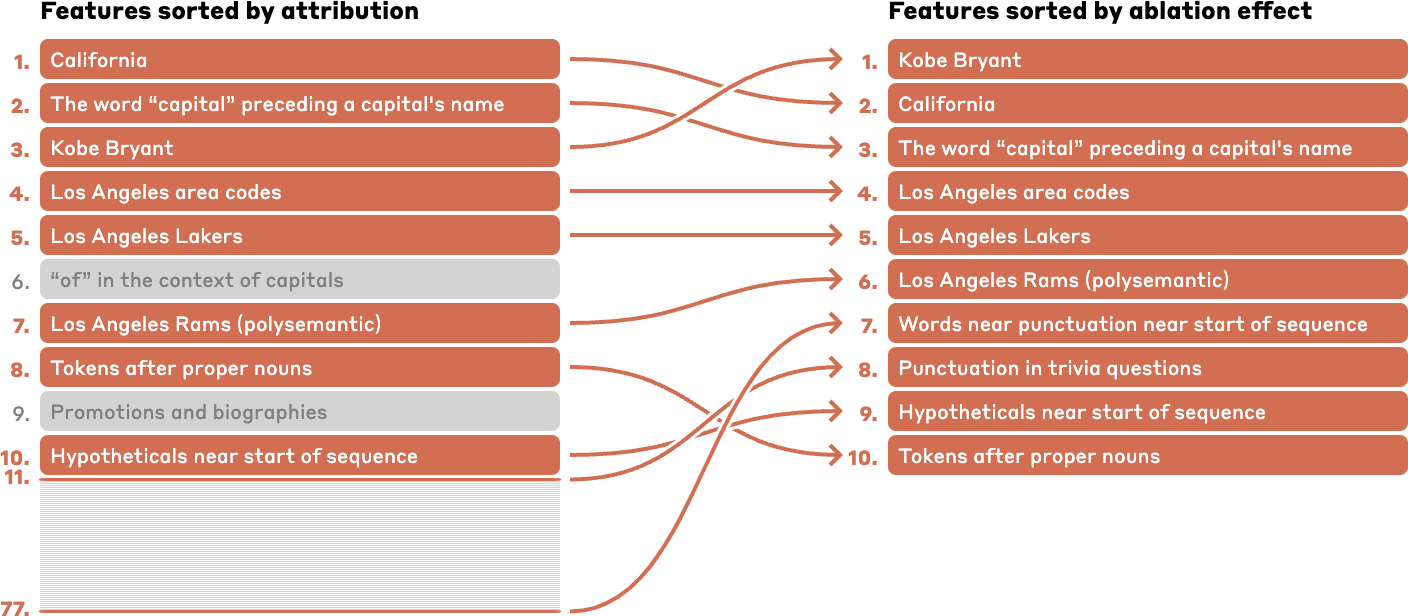
Identifying specific LLM features can also help researchers map out the chain of inference that the model uses to answer complex questions. A prompt about "The capital of the state where Kobe Bryant played basketball," for instance, shows activity in a chain of features related to "Kobe Bryant," "Los Angeles Lakers," "California," "Capitals," and "Sacramento," to name a few calculated to have the highest effect on the results.

Recommended Comments
There are no comments to display.
Join the conversation
You can post now and register later. If you have an account, sign in now to post with your account.
Note: Your post will require moderator approval before it will be visible.