
3175x175(CURRENT).thumb.jpg.b05acc060982b36f5891ba728e6d953c.jpg)

OpenZFS founding developer Matthew Ahrens opened a PR for one of the most sought-after features in ZFS history—RAIDz expansion—last week. The new feature allows a ZFS user to expand the size of a single RAIDz vdev. For example, you can use the new feature to turn a three-disk RAIDz1 into a four, five, or six RAIDz1.
OpenZFS is a complex filesystem, and things are necessarily going to get a bit chewy explaining how the feature works. So if you're a ZFS newbie, you may want to refer back to our comprehensive ZFS 101 introduction.
Expanding storage in ZFS
In addition to being a filesystem, ZFS is a storage array and volume manager, meaning that you can feed it a whole pile of disk devices, not just one. The heart of a ZFS storage system is the zpool—this is the most fundamental level of ZFS storage. The zpool in turn contains vdevs, and vdevs contain actual disks within them. Writes are split into units called records or blocks, which are then distributed semi-evenly among the vdevs.
A storage vdev can be one of five types—a single disk, mirror, RAIDz1, RAIDz2, or RAIDz3. You can add more vdevs to a zpool, and you can attach more disks to a single or mirror vdev. But managing storage this way requires some planning ahead and budgeting—which hobbyists and homelabbers frequently aren't too enthusiastic about.
Conventional RAID, which does not share the "pool" concept with ZFS, generally offers the ability to expand and/or reshape an array in place. For example, you might add a single disk to a six-disk RAID6 array, thereby turning it into a seven-disk RAID6 array. Undergoing a live reshaping can be pretty painful, especially on nearly full arrays; it's entirely possible that such a task might require a week or more, with array performance limited to a quarter or less of normal the entire time.
Historically, ZFS has eschewed this sort of expansion. ZFS was originally developed for business use, and live array re-shaping is generally a non-starter in the business world. Dropping your storage's performance to unusable levels for days on end generally costs more in payroll and overhead than buying an entirely new set of hardware would. Live expansion is also potentially very dangerous since it involves reading and re-writing all data and puts the array in a temporary and far less well-tested "half this, half that" condition until it completes.
For users with many disks, the new RAIDz expansion is unlikely to materially change how they use ZFS. It will still be both easier and more practical to manage vdevs as complete units rather than trying to muck about inside them. But hobbyists, homelabbers, and small users who run ZFS with a single vdev will likely get a lot of use out of the new feature.
How does it work?
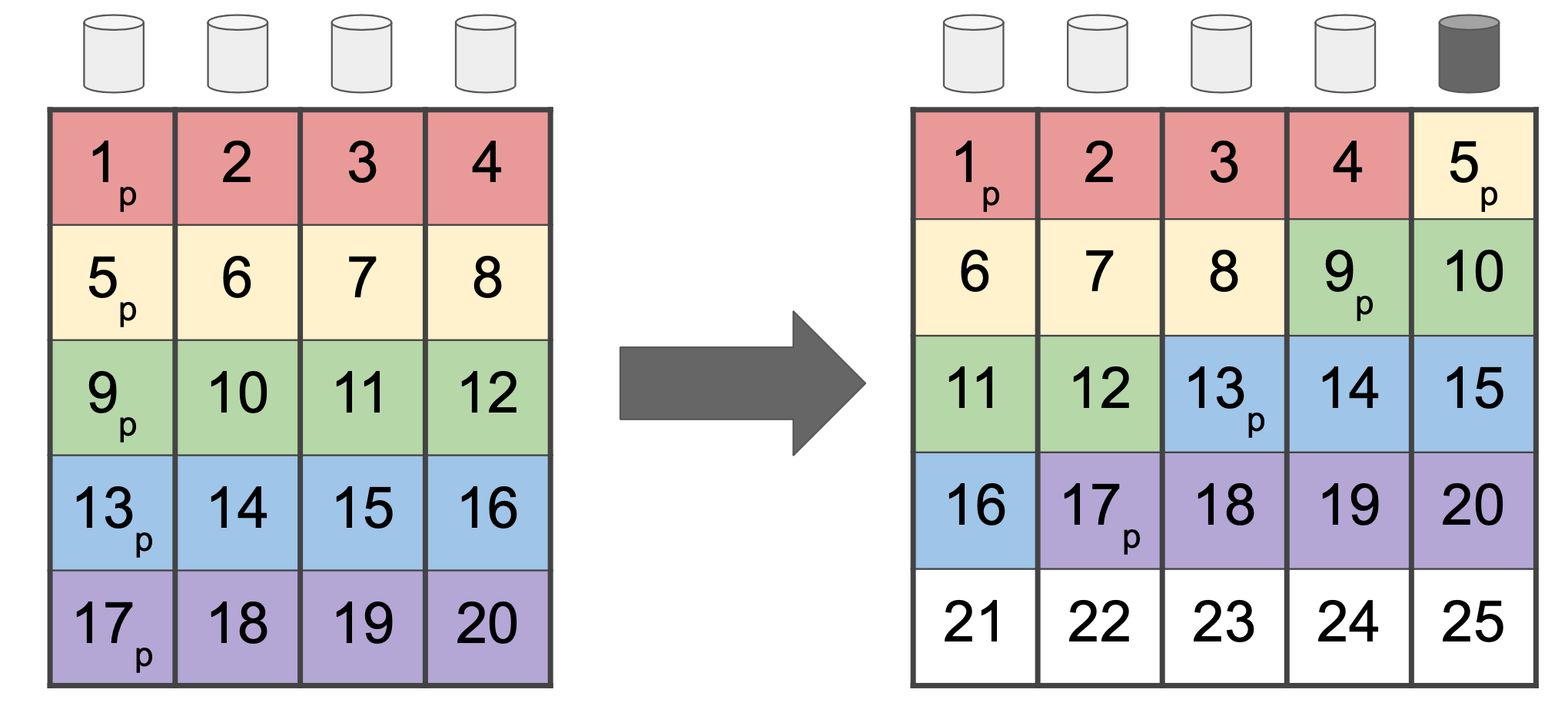
From a practical perspective, Ahrens' new vdev expansion feature merely adds new capabilities to an existing command, namely, zpool attach, which is normally used to add a disk to a single-disk vdev (turning it into a mirror vdev) or add an extra disk to a mirror (for example, turning a two-disk mirror into a three-disk mirror).
With the new code, you'll be able to attach new disks to an existing RAIDz vdev as well. Doing so expands the vdev in width but does not change the vdev type, so you can turn a six-disk RAIDz2 vdev into a seven-disk RAIDz2 vdev, but you can't turn it into a seven-disk RAIDz3.
Upon issuing your zpool attach command, the expansion begins. During expansion, each block or record is read from the vdev being expanded and is then rewritten. The sectors of the rewritten block are distributed among all disks in the vdev, including the new disk(s), but the width of the stripe itself is not changed. So a RAIDz2 vdev expanded from six disks to ten will still be full of six-wide stripes after expansion completes.
So while the user will see the extra space made available by the new disks, the storage efficiency of the expanded data will not have improved due to the new disks. In the example above, we went from a six-disk RAIDz2 with a nominal storage efficiency of 67 percent (four of every six sectors are data) to a ten-disk RAIDz2. Data newly written to the ten-disk RAIDz2 has a nominal storage efficiency of 80 percent—eight of every ten sectors are data—but the old expanded data is still written in six-wide stripes, so it still has the old 67 percent storage efficiency.
It's worth noting that this isn't an unexpected or bizarre state for a vdev to be in—RAIDz already uses a dynamic, variable stripe width to account for blocks or records too small to stripe across all the disks in a single vdev.
For example, if you write a single metadata block—the data containing a file's name, permissions, and location on disk—it fits within a single sector on disk. If you write that metadata block to a ten-wide RAIDz2, you don't write a full ten-wide stripe—instead, you write an undersized block only three disks wide; a single data sector plus two parity sectors. So the "undersized" blocks in a newly expanded RAIDz vdev aren't anything for ZFS to get confused about. They're just another day at the office.
Is there any lasting performance impact?
As we discussed above, a newly expanded RAIDz vdev won't look quite like one designed that way from "birth"—at least, not at first. Although there are more disks in the mix, the internal structure of the data isn't changed.
Adding one or more new disks to the vdev means that it should be capable of somewhat higher throughput. Even though the legacy blocks don't span the entire width of the vdev, the added disks mean more spindles to distribute the work around. This probably won't make for a jaw-dropping speed increase, though—six-wide stripes on a seven-disk vdev mean that you still can't read or write two blocks simultaneously, so any speed improvements are likely to be minor.
The net impact to performance can be difficult to predict. If you are expanding from a six-disk RAIDz2 to a seven-disk RAIDz2, for example, your original six-disk configuration didn't need any padding. A 128KiB block can be cut evenly into four 32KiB data pieces, with two 32KiB parity pieces. The same record split among seven disks requires padding because 128KiB/five data pieces doesn't come out to an even number of sectors.
Similarly, in some cases—particularly with a small recordsize or volblocksize set—the workload per individual disk may be significantly less challenging in the older, narrower layout than in the newer, wider one. A 128KiB block split into 32KiB pieces for a six-wide RAIDz2 can be read or written more efficiently per disk than one split into 16KiB pieces for a ten-wide RAIDz2, for example—so it's a bit of a crapshoot whether more disks but smaller pieces will provide more throughput than fewer disks but larger pieces did.
The one thing you can be certain of is that the newly expanded configuration should typically perform as well as the original non-expanded version—and that once the majority of data is (re)written in the new width, the expanded vdev won't perform any differently, or be any less reliable, than one that was designed that way from the start.
Why not reshape records/blocks during expansion?
It might seem odd that the initial expansion process doesn't rewrite all existing blocks to the new width while it's running—after all, it's reading and re-writing the data anyway, right? We asked Ahrens why the original width was left as-is, and the answer boils down to "it's easier and safer that way."
One key factor to recognize is that technically, the expansion isn't moving blocks; it's just moving sectors. The way it's written, the expansion code doesn't need to know where ZFS' logical block boundaries are—the expansion routine has no idea whether an individual sector is parity or data, let alone which block it belongs to.
Expansion could traverse all the block pointers to locate block boundaries, and then it would know which sector belongs to what block and how to re-shape the block, but according to Ahrens, doing things that way would be extremely invasive to ZFS' on-disk format. The expansion would need to continually update spacemaps on metaslabs to account for changes in the on-disk size of each block—and if the block is part of a dataset rather than a zvol, update the per-dataset and per-file space accounting as well.
If it really makes your teeth itch knowing you have four-wide stripes on a freshly five-wide vdev, you can just read and re-write your data yourself after expansion completes. The simplest way to do this is to use zfs snapshot, zfs send, and zfs receive to replicate entire datasets and zvols. If you're not worried about ZFS properties, a simple mv operation will do the trick.
However, we'd recommend in most cases just relaxing and letting ZFS do its thing. Your undersized blocks from older data aren't really hurting anything, and as you naturally delete and/or alter data over the life of the vdev, most of them will get re-written naturally as necessary, without the need for admin intervention or long periods of high storage load due to obsessively reading and re-writing everything all at once.
When will RAIDz expansion hit production?
Ahrens' new code is not yet a part of any OpenZFS release, let alone added to anyone else's repositories. We asked Ahrens when we might expect to see the code in production, and unfortunately, it will be a while.
It's too late for RAIDz expansion to be included in the upcoming OpenZFS 2.1 release, expected very soon (2.1 release candidate 7 is available now). It should be included in the next major OpenZFS release; it's too early for concrete dates, but major releases typically happen about once per year.
Broadly speaking, we expect RAIDz expansion to hit production in the likes of Ubuntu and FreeBSD somewhere around August 2022, but that's just a guess. TrueNAS may very well put it into production sooner than that, since ixSystems tends to pull ZFS features from master before they officially hit release status.

Recommended Comments
There are no comments to display.
Join the conversation
You can post now and register later. If you have an account, sign in now to post with your account.
Note: Your post will require moderator approval before it will be visible.