

Bitsight Security Research
The big outage
As we are all very aware, being a technical person or layman, the recent CrowdStrike outage caused disruptions on a myriad of systems worldwide, affecting multiple industry sectors and millions of people in some way, shape, or format.
On July 19, 2024, as a result of a faulty update to CrowdStrike Falcon sensor configuration for Windows systems, intended to enhance security by targeting newly observed malicious activities, there was an inadvertent logic error that led to widespread system crashes and blue screens of death (BSOD) on affected machines.
Bitsight estimates that this chain of events immediately impacted and led to a significant drop in the number of systems and organizations that connected to CrowdStrike Falcon servers—between 15% and 20%.
Throughout this article, we will dive into our observations around the fatidical date and the strange patterns we observed just days before the big outage happened.
According to CrowdStrike and other sources, the timeline of events was as follows:
July 19, 2024, 04:09 UTC: CrowdStrike released a sensor configuration update, Channel File 291, to Windows systems as part of their ongoing operations. This update triggered a logic error that caused system crashes on impacted machines.
July 19, 2024, 05:27 UTC: CrowdStrike identified the issue and reverted the changes, but by then, many systems had already been affected. The update impacted Windows 10 and later versions, but did not affect Mac and Linux systems, which also happen to have an inherently different kernel architecture.
Immediate Impact: The faulty update caused significant disruptions globally. Approximately 8.5 million devices were affected, leading to outages in various sectors, including airlines, healthcare, and financial institutions. Notably, 5,078 flights were canceled worldwide, and operations at numerous airports were disrupted. Delta Airlines is still struggling to return to normal operation as of July 23.
July 19-22, 2024: CrowdStrike and Microsoft worked together to provide remediation steps. Affected machines required manual intervention to delete the faulty .sys file from the CrowdStrike directory. This process involved booting into Safe Mode or the Windows Recovery Environment, making recovery a time-consuming task for large organizations. There are reports that cloud remediation is possible, but users must opt-in by submitting a request via the support portal and requesting to be included in cloud remediation and then rebooting.
This is the official timeline for this event. Bitsight is always monitoring all sorts of security-related events and, although this was not exactly a new vulnerability or anything of the sort, we wondered if we might have some visibility into what was happening.
So Bitsight TRACE got to work and got creative on ways we could measure the impact of this outage, what could we share about it, and how we could help our customers in any way, if possible.
The where and what
If you know Bitsight, you know we have an extraordinary amount of diverse datasets and capabilities. We use them to measure all kinds of security-related events that go on to comprise our rating. But that’s not all, we also use our capabilities in Bitsight TRACE for extensive research, on many different topics, like doing KEV analysis or helping our customers understand how the Kaspersky ban impacts them or analyzing latest malware at Internet wide scale.
Needless to say, we started looking into this latest incident too and our findings were curious, at least.
CrowdStrike publishes the Cloud IP Addresses and the fully qualified domain names (FQDNs) that allow the Falcon sensor software to communicate with the CrowdStrike cloud for everyday operation. This allows system administrators to properly set up their firewall/IDS and add these FQDNs and/or IP addresses to allow for network communications.
By looking into traffic samples to and from these IP addresses, we can have some visibility on the recent incident, as well as map those IPs to organizations and have an indication of who uses CrowdStrike Falcon products and who was affected by the outage. Of course, there are some caveats such as collection bias, packet loss, and other issues that affect our visibility, but we consider our sample large enough to draw some conclusions.
The dataset
The dataset for our analysis has a time period between the 29th of June and 22nd of July, 2024. The mentioned time period (~3 weeks), for the reader to understand what we call large enough, has the following overall counts:
Total number of contacts: 791.766.880
Total number of unique IPs: 603.131
Total number of countries: 153
With almost a billion IP contacts to the CrowdStrike Falcon servers and 600 thousand unique IP addresses to process, it was time to crunch the numbers and see what we could see.
The observations
Daily new IPs
The amount of newly unique IPs detected each day that contacted CrowdStrike Falcon servers drops very fast, suggesting that increasing the time period won’t yield a significant increase in visibility and we have reached a good compromise for our sample.
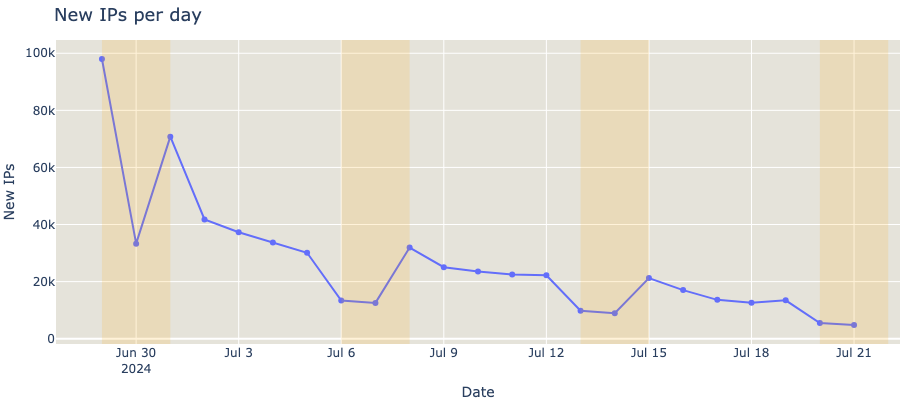
It also seems to confirm the frequent update requests that the Falcon agent issues, which makes complete sense for the type of cutting-edge software it is. Any decent anti-virus or equivalent solution must have their malware signatures up to date as frequently as possible if they want to stand a chance in this game.
Packets and bytes
We have an interesting number of unique IPs, let’s look into the packet count and amount of bytes exchanged between them and the CrowdStrike servers. That will help us understand the communication patterns and any outliers that might be seen.
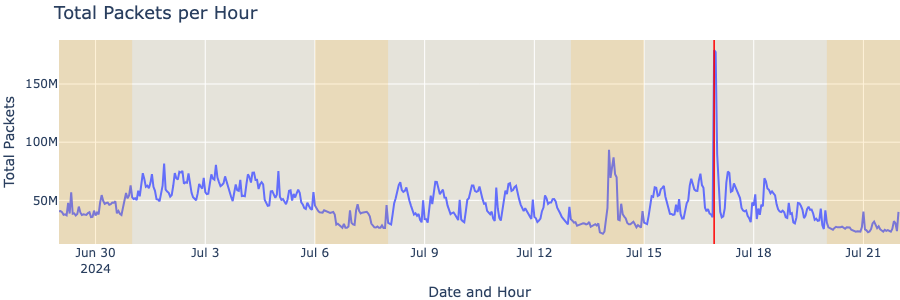
The hourly packet count floats around ~60M on weekdays and ~30M on weekends for most days, but we can easily see a spike around July 16th.
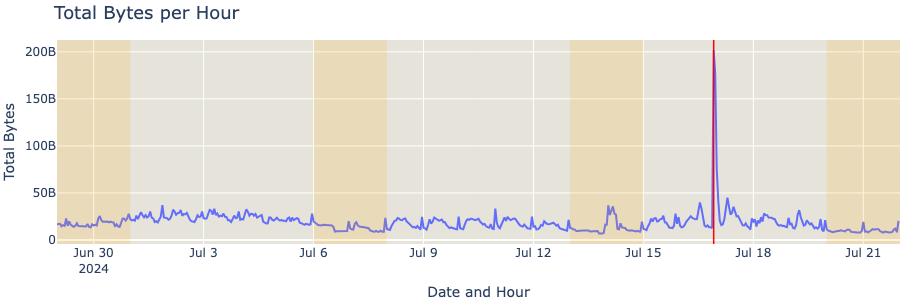
We can also observe that a peek in total bytes occurred at the exact same period, on Jul 16, 2024, at around 22:00 UTC. There might be several explanations as to why this has happened and, at this moment, we can only speculate. It is likely that this traffic spike might be related to an update that fixed a bug, which led to high CPU consumption on Windows hosts, as reported by The Stack.
Unique IPs
When we plot the number of unique IPs per minute, we can see the weekly/weekend pattern. If we notice carefully, at around 22:00 on the 16th (the first green dashed line, left to right), a sharp spike appears. After that spike, there was a significant decrease in the maximum number of IPs per minute compared to the previous day's (and weekday) pattern.
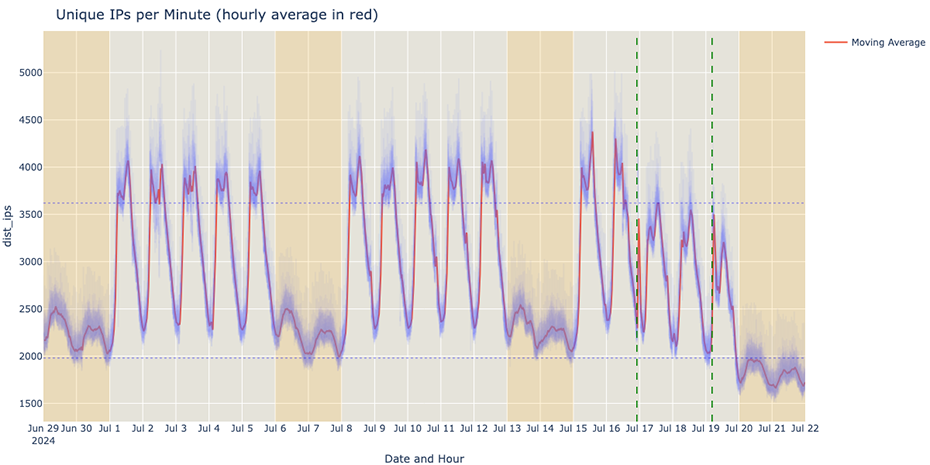
Two days and some hours after that, in the chaotic dawn of the 19th, between around 4am and 5am, there was an upward spike ( typical around that time), followed by the unexpected drop shortly after (second dashed green line, left to right).
zoomed in chart:
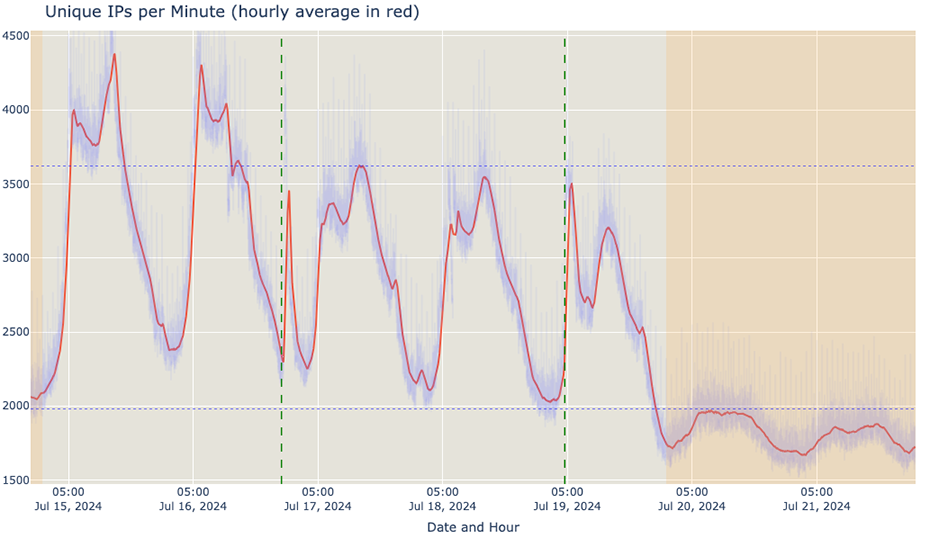
After these events, there was a significant decrease in the maximum amount of IPs per minute this past weekend. In particular, the maximum number of unique IPs per minute (on average) did not reach the minimum number of unique IPs on the previous weekends.
If we overlap each day onto a chart, the difference is more visible. Below, marked blue, are all weekdays up to the 16th. The 17th and 18th are marked orange, and the 19th is green.
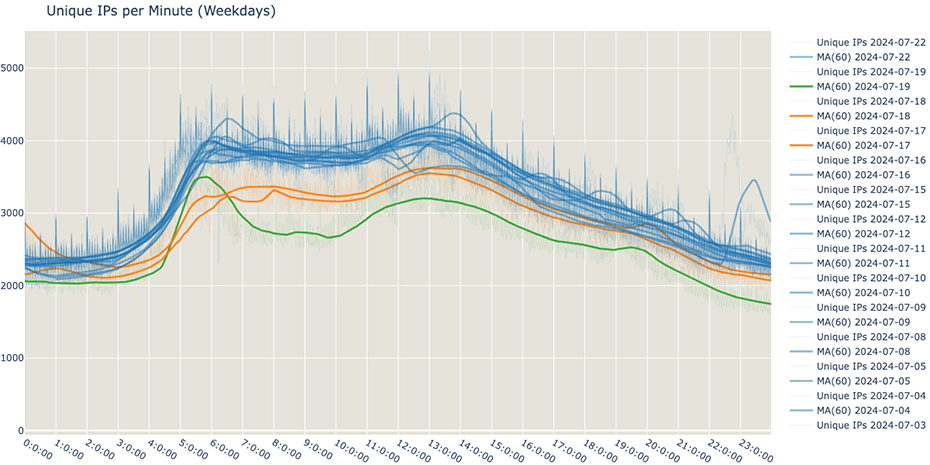
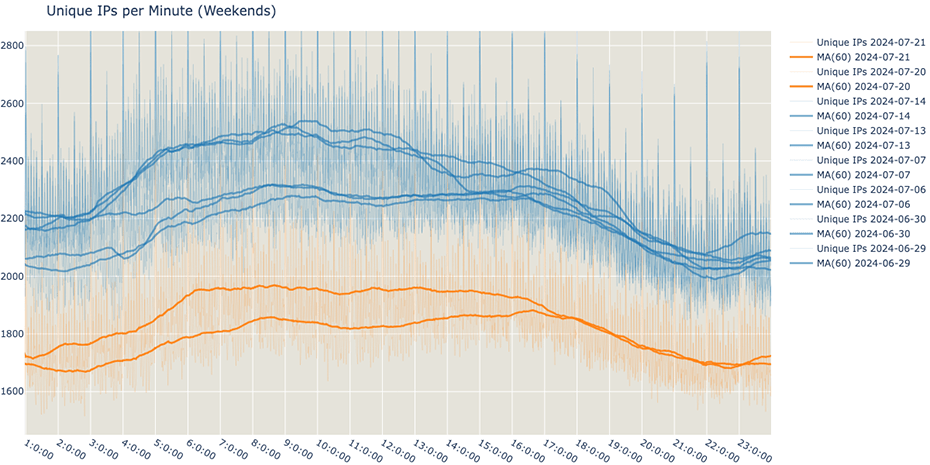
Looking at this past weekend and comparing it to the previous three weekends, a similar drop in the unique IPs per minute can be observed.
Furthermore, when comparing the number of organizations we can observe (we monitored more than 3500 organizations in this sample), there was a similar drop.
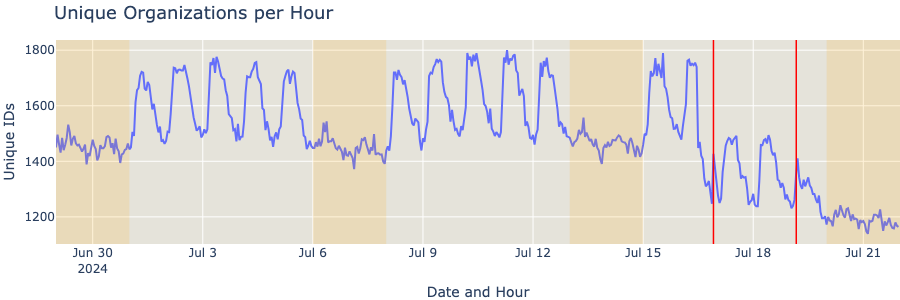
Looking at all the telemetry, two observations emerge very quickly. First, there is a drop in traffic that started on July 16th, three days before the update in question was rolled out, and second, on July 19th, CrowdStrike servers globally had another decrease in traffic, likely due to the faulty update that took millions of machines offline.
Conclusions
As Bitsight continues to investigate the traffic patterns exhibited by CrowdStrike machines across organizations globally, two distinct points emerge as “interesting” from a data perspective. Firstly, on July 16th at around 22:00 there was a huge traffic spike, followed by a clear and significant drop off in egress traffic from organizations to CrowdStrike. Second, there was a significant drop, between 15% and 20%, in the number of unique IPs and organizations connected to CrowdStrike Falcon servers, after the dawn of the 19th.
While we can not infer what the root cause of the change in traffic patterns on the 16th can be attributed to, it does warrant the foundational question of “Is there any correlation between the observations on the 16th and the outage on the 19th?”. As more details from the event emerge, Bitsight will continue investigating the data.
Organizations globally continue to become hyper-digitized and reliant on external software for day-to-day operations, and, as such it has become increasingly important that both the organization itself and the software vendors that the organization relies on for day-to-day operations practice proper technology hygiene exhibited in the form of staged updates, phased rolls outs, proper back-ups and well-organized plans for operational disruptions.
As system administrators rush to fix their servers, our thoughts cannot help but to be with them. We honestly hope everyone recovers fairly quickly from this incident, lessons are learned and processes are adjusted accordingly.
Recommended Comments
There are no comments to display.
Join the conversation
You can post now and register later. If you have an account, sign in now to post with your account.
Note: Your post will require moderator approval before it will be visible.