

AI image generation is here in a big way. A newly released open source image synthesis model called Stable Diffusion allows anyone with a PC and a decent GPU to conjure up almost any visual reality they can imagine. It can imitate virtually any visual style, and if you feed it a descriptive phrase, the results appear on your screen like magic.
Some artists are delighted by the prospect, others aren't happy about it, and society at large still seems largely unaware of the rapidly evolving tech revolution taking place through communities on Twitter, Discord, and Github. Image synthesis arguably brings implications as big as the invention of the camera—or perhaps the creation of visual art itself. Even our sense of history might be at stake, depending on how things shake out. Either way, Stable Diffusion is leading a new wave of deep learning creative tools that are poised to revolutionize the creation of visual media.
The rise of deep learning image synthesis
Stable Diffusion is the brainchild of Emad Mostaque, a London-based former hedge fund manager whose aim is to bring novel applications of deep learning to the masses through his company, Stability AI. But the roots of modern image synthesis date back to 2014, and Stable Diffusion wasn't the first image synthesis model (ISM) to make waves this year.
In April 2022, OpenAI announced DALL-E 2, which shocked social media with its ability to transform a scene written in words (called a “prompt”) into a myriad of visual styles that can be fantastic, photorealistic, or even mundane. People with privileged access to the closed-off tool generated astronauts on horseback, teddy bears buying bread in ancient Egypt, novel sculptures in the style of famous artists, and much more.

Not long after DALL-E 2, Google and Meta announced their own text-to-image AI models. MidJourney, available as a Discord server since March 2022 and open to the public a few months later, charges for access and achieves similar effects but with a more painterly and illustrative quality as the default.
Then there's Stable Diffusion. On August 22, Stability AI released its open source image generation model that arguably matches DALL-E 2 in quality. It also launched its own commercial website, called DreamStudio, that sells access to compute time for generating images with Stable Diffusion. Unlike DALL-E 2, anyone can use it, and since the Stable Diffusion code is open source, projects can build off it with few restrictions.
In the past week alone, dozens of projects that take Stable Diffusion in radical new directions have sprung up. And people have achieved unexpected results using a technique called "img2img" that has "upgraded" MS-DOS game art, converted Minecraft graphics into realistic ones, transformed a scene from Aladdin into 3D, translated childlike scribbles into rich illustrations, and much more. Image synthesis may bring the capacity to richly visualize ideas to a mass audience, lowering barriers to entry while also accelerating the capabilities of artists that embrace the technology, much like Adobe Photoshop did in the 1990s.

You can run Stable Diffusion locally yourself if you follow a series of somewhat arcane steps. For the past two weeks, we've been running it on a Windows PC with an Nvidia RTX 3060 12GB GPU. It can generate 512×512 images in about 10 seconds. On a 3090 Ti, that time goes down to four seconds per image. The interfaces keep evolving rapidly, too, going from crude command-line interfaces and Google Colab notebooks to more polished (but still complex) front-end GUIs, with much more polished interfaces coming soon. So if you're not technically inclined, hold tight: Easier solutions are on the way. And if all else fails, you can try a demo online.
How stable diffusion works
Broadly speaking, most of the recent wave of ISMs use a technique called latent diffusion. Basically, the model learns to recognize familiar shapes in a field of pure noise, then gradually brings those elements into focus if they match the words in the prompt.
To get started, a person or group training the model gathers images with metadata (such as alt tags and captions found on the web) and forms a large data set. In Stable Diffusion's case, Stability AI uses a subset of the LAION-5B image set, which is basically a huge image scrape of 5 billion publicly accessible images on the Internet. Recent analysis of the data set shows that many of the images come from sites such as Pinterest, DeviantArt, and even Getty Images. As a result, Stable Diffusion has absorbed the styles of many living artists, and some of them have spoken out forcefully against the practice. More on that below.
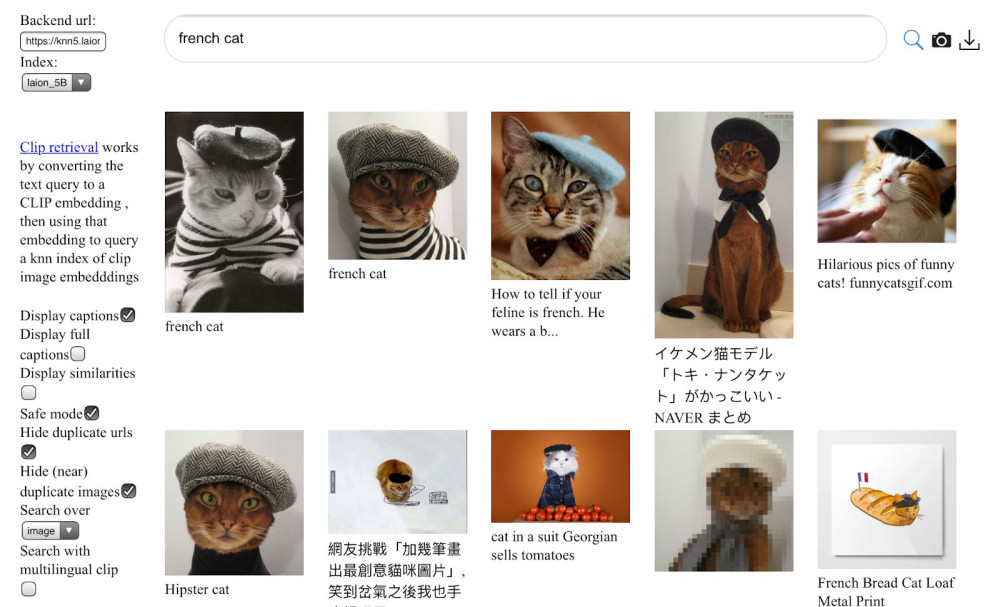
Next, the model trains itself on the image data set using a bank of hundreds of high-end GPUs such as the Nvidia A100. According to Mostaque, Stable Diffusion cost $600,000 to train so far (estimates of training costs for other ISMs typically range in the millions of dollars). During the training process, the model associates words with images thanks to a technique called CLIP (Contrastive Language–Image Pre-training), which was invented by OpenAI and announced just last year.
Through training, an ISM using latent diffusion learns statistical associations about where certain colored pixels usually belong in relation to each other for each subject. So it doesn't necessarily "understand" their relationship at a high level, but the results can still be stunning and surprising, making inferences and style combinations that seem very intelligent. After the training process is complete, the model never duplicates any images in the source set but can instead create novel combinations of styles based on what it has learned. The results can be delightful and wildly fun.
At the moment, Stable Diffusion doesn't care if a person has three arms, two heads, or six fingers on each hand, so unless you're a wizard at crafting the text prompts necessary to generate great results ( which AI artists sometimes call "prompt engineering"), you'll probably need to generate lots of images and cherry-pick the best ones. Keep in mind that the more a prompt matches captions for known images in the data set, the more likely you'll get the result you want. In the future, it's likely that models will improve enough to reduce the need for cherry-picking—or some kind of internal filter will do the picking for you.
As hinted at above, Stable Diffusion's public release has raised alarm bells among people who fear its cultural and economic impact. Unlike DALL-E 2, Stable Diffusion's training data (the "weights") are available for anyone to use without any hard restrictions. The official Stable Diffusion release (and DreamStudio) includes automatic "NSFW" filters (nudity) and an invisible tracking watermark embedded in the images, but these restrictions can easily be circumvented in the open source code.
This means Stable Diffusion can be used to create images that OpenAI currently blocks with DALL-E 2: propaganda, violent imagery, pornography, images that potentially violate corporate copyright, celebrity deepfakes, and more. In fact, there are already some private Discord servers dedicated to pornographic output from the model.
To be clear, Stable Diffusion's license officially forbids many of these uses, but with the code and weights out in the wild, enforcement will prove very difficult, if not impossible. When presented with these concerns, Mostaque said that he feels the benefits of having this kind of tool out in the open where it can be scrutinized outweigh the potential drawbacks. In a short interview, he told us, "We believe in individual responsibility and agency. We included an ethical use policy and tools to mitigate harm."
Also, Stable Diffusion has drawn the ire of artists on Twitter due to the model's ability to imitate the style of living artists, as mentioned above. (And despite the claims of some viral tweets, Stability AI has never advertised this ability. One of the most shared tweets mistakenly pulled from an independent study done by an AI researcher.) In the quest for data, the image set used to train Stable Diffusion includes millions of pieces of art gathered from living artists without consultation with the artists, which raises profound ethical questions about authorship and copyright. Scraping the data appears lawful by US legal precedent, but one could argue that the law might be lagging behind rapidly evolving technology that upends previous assumptions about how public data might be utilized.
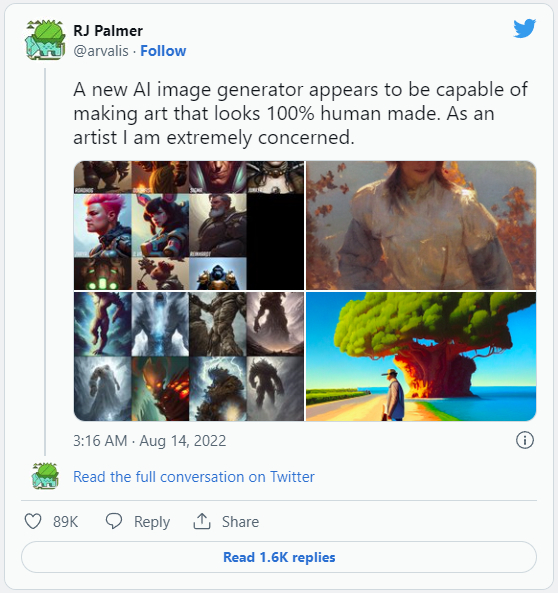
As a result, if image synthesis technology becomes adopted by major corporations in the future (which may be coming soon—"We have a collaborative relationship with Adobe," says Mostaque), companies might train their own models based on a "clean" data set that includes licensed content, opt-in content, and public domain imagery to avoid some of these ethical issues, even if using an Internet scrape is technically legal. We asked Mostaque if he had any plans along these lines, and he replied, "Stability is working on a range of models. All models by ourselves and our collaborators are legal within their jurisdictions."
Another issue with diffusion models from all vendors is cultural bias. Since these ISMs currently work by scraping the Internet for images and their related metadata, they learn social and cultural stereotypes present in the data set. For example, early on in the Stable Diffusion beta on its Discord server, testers found that almost every request for a "beautiful woman" involved unintentional nudity of some kind, which reflects how Western society often depicts women on the Internet. Other cultural and racist stereotypes abound in ISM training data, so researchers caution that it should not be used in a production environment without significant safeguards in place, which is likely one reason why other powerful models such as DALLE-2 and Google's Imagen are still not broadly available to the public.
While concerns about data set quality and bias echo strongly among some AI researchers, the Internet remains the largest source of images with metadata attached. This trove of data is freely accessible, so it will always be a tempting target for developers of ISMs. Attempting to manually write descriptive captions for millions or billions of images for a brand new ethical data set is probably not economically feasible at the moment, so it's the heavily biased data on the Internet that is currently making this technology possible. Since there is no universal worldview across cultures, to what degree image synthesis models filter or interpret certain ideas will likely remain a value judgment among the different communities that use the technology in the future.
If historical trends in computing are any suggestion, odds are high that what now takes a beefy GPU will eventually be possible on a pocket smartphone. "It is likely that Stable Diffusion will run on a smartphone within a year," Mostaque told us. Also, new techniques will allow training these models on less expensive equipment over time. We may soon be looking at an explosion in creative output fueled by AI.
Stable Diffusion and other models are already starting to take on dynamic video generation and manipulation, so expect photorealistic video generation via text prompts before too long. From there, it's logical to extend these capabilities to audio and music, real-time video games, and 3D VR experiences. Soon, advanced AI may do most of the creative heavy lifting with just a few suggestions. Imagine unlimited entertainment generated in real-time, on demand. "I expect it to be fully multi-modal," said Mostaque, "So you can create anything you can imagine, like the Star Trek holodeck experience."
ISMs are also a dramatic form of image compression: Stable Diffusion takes hundreds of millions of images and squeezes knowledge about them into a 4.2GB weights file. With the correct seed and settings, certain generated images can be reproduced deterministically. One could imagine using a variation of this technology in the future to compress, say, an 8K feature film into a few megabytes of text. Once that's the case, anyone could compose their own feature films that way as well. The implications of this technology are only just beginning to be explored, so it may take us in wild new directions we can't foresee at the moment.

Realistic image synthesis models are potentially dangerous for reasons already mentioned, such as the creation of propaganda or misinformation, tampering with history, accelerating political division, enabling character attacks and impersonation,
and destroying the legal value of photo or video evidence. In the AI-powered future, how will we know if any remotely produced piece of media came from an actual camera, or if we are actually communicating with a real human? On these questions, Mostaque is broadly hopeful. "There will be new verification systems in place, and open releases like this will shift the public debate and development of these tools," he said.
That's easier said than done, of course. But it's also easy to be scared of new things. Despite our best efforts, it's difficult to know exactly how image synthesis and other AI-powered technologies will affect us on a societal scale without seeing them in wide use. Ultimately, humanity will adapt, even if our cultural frameworks end up changing radically in the process. It's happened before, which is why the Ancient Greek philosopher Heraclitus reportedly said, "the only constant is change."
In fact, there's a photo of him saying that now, thanks to Stable Diffusion.
Source: Ars Technica


Recommended Comments
There are no comments to display.
Join the conversation
You can post now and register later. If you have an account, sign in now to post with your account.
Note: Your post will require moderator approval before it will be visible.