3175x175(CURRENT).thumb.jpg.b05acc060982b36f5891ba728e6d953c.jpg)
The central dogma of molecular biology holds that DNA gets transcribed into RNA, which then gets translated into proteins. Of course, there are exceptions—some viruses, like coronaviruses, forego DNA altogether and encode their genetic information in RNA genomes. Other viruses, like HIV, have RNA genomes that must be copied into DNA and then transcribed back into RNA before being made into proteins. But as a general rule, "DNA to RNA to protein" describes how information moves within cells.
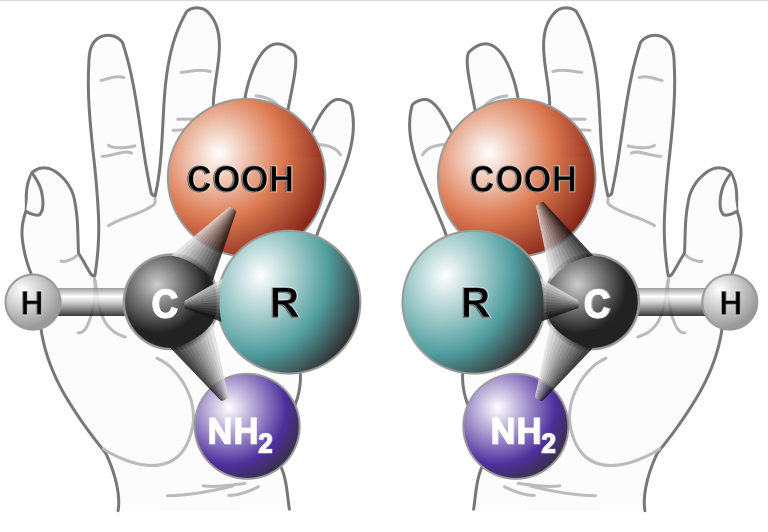
A unique property of biological molecules is that they have handedness. Naturally occurring molecules occur in roughly equal mixtures of left- and right-handed varieties. This means that molecules can have identical atoms and shapes but cannot be superimposed one upon the other. Instead, they are mirror images of each other, like our right and left hands.
(This can be difficult to envision, which is why pre-meds taking organic chemistry in college spend so much time playing with those ball-and-stick molecular models.)
Unlike naturally occurring molecules, biological molecules are all one-sided. Our nucleic acids are all right-handed (referred to as D, from the Latin dexter), and proteins are all left-handed (L for laevus). This is such a unique feature of biological molecules that SETI uses it as a hallmark signature when it is searching for life. Louis Pasteur first noticed this one-sidedness in 1848, and scientists have been speculating about mirror life ever since. Now, they have gotten one step closer to creating it.
A jump to the left, a step to the right
Ting F. Zhu’s lab at Tsinghua University in Beijing has been synthesizing all of the components necessary for a mirror-image central dogma. The researchers have used synthetic chemical methods to synthesize short stretches of mirror-image L-DNA and L-RNA. But it’s more efficient to make nucleic acids using enzymes called polymerases—that is, proteins. The naturally occurring proteins we use for this only work with D-DNA.
So the lab used synthetic chemistry to make mirror-image D-protein DNA polymerases and used them to replicate short strands of L-DNA. In other words, a mirror image of a normal protein can copy the mirror image of normal DNA. Separately, the researchers tweaked their D-protein DNA polymerases to turn them into RNA polymerases so they could transcribe short strands of L-DNA into L-RNA. These polymerases were amazing proofs of concept, but they were inefficient and error prone, and they could only generate short pieces of L-nucleic acids.
Now, the Zhu lab has chemically synthesized a mirror-image of an enzyme called Pfu DNA polymerase, which is commonly used for PCR reactions. This enzyme is heat-resistant and has very high fidelity. But it’s also about twice as big as the polymerases the researchers had made before; the scientists had to synthesize it in two pieces and then link them together.
The researchers used the enzyme to copy a mirror-image gene that is 1,500 bases long, about 10 times as long as the earlier polymerases could manage. The gene the researchers chose encodes ribosomal RNA, so when they can transcribe it, they will have one part of a mirror-image ribosome. Once they get all the parts, they won’t have to rely on bulky synthetic methods to make mirror-image D-proteins anymore.
Long-lived
One potential use of mirror-image L-DNA is that, like its natural counterpart D-DNA, it can be used as a compact and reliable means of information storage. But unlike its natural counterpart, it can’t be degraded by enzymes, because no one has made mirror-image D-DNases that can degrade them yet. To demonstrate one application, Zhu made DNA barcodes for environmental water samples—you can think of the bar codes as using the sequence of bases to indicate things like “lotus pond, Beijing.” When he tried to amplify the normal, D-DNA barcode from a pond sample a day after adding it, it could not be found; it had been degraded. The mirror-image L-DNA barcode was still detectable a year later.
As if that weren’t clever enough, he and his lab ventured into steganography. They made a key molecule of DNA that is half-D and half-L; half-normal and half-mirror image. As a reference text, they encoded Pasteur’s 1860 paragraph speculating about mirror life into D-DNA. If the key is read with a normal DNA polymerase, it gives an error message when decoded using the Pasteur text. But if it is read with an L-DNA polymerase, it gives the secret message from the mirror DNA.
Obviously, Zhu’s team now intends to make mirror-image ribosomes to translate mirror-image mRNAs into mirror-image proteins. This is no small feat—ribosomes are very complex, involving dozens of proteins and several RNA molecules—but still, the researchers have gotten pretty far pretty fast. And of course, they also plan to make mirror-image D-DNases to “eliminate the information-storing L-DNA molecules after use as a biocontainment strategy.”
Nature Biotechnology, 2021 DOI: 10.1038/s41587-021-00969-6

{kind=link}
Recommended Comments
There are no comments to display.
Join the conversation
You can post now and register later. If you have an account, sign in now to post with your account.
Note: Your post will require moderator approval before it will be visible.