
3175x175(CURRENT).thumb.jpg.b05acc060982b36f5891ba728e6d953c.jpg)
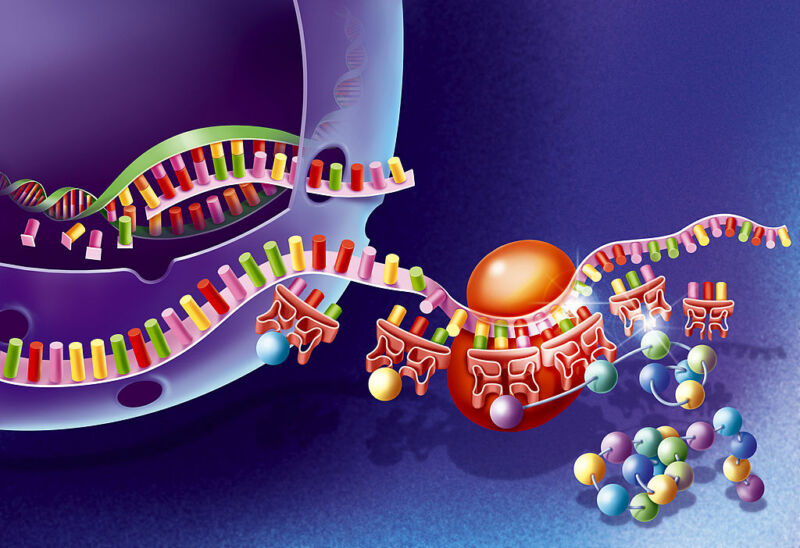
All living things on Earth use a version of the same genetic code. Every cell makes proteins using the same 20 amino acids. Ribosomes, the protein-making machinery within cells, read the genetic code from a messenger RNA molecule to determine which amino acid to put next into the particular protein they are building.
This code is universal, which is why the ribosomes in our cells can read a piece of viral messenger RNA and make a functional viral protein from it. There are plenty of other amino acids, though. While life does not generally use them, scientists have been incorporating these into proteins. Now, researchers have figured out a way to greatly expand the genetic code, allowing widespread incorporation of these non-biological amino acids. They accomplish this by running a second set of everything—proteins and RNAs—needed to translate the genetic code.
A system apart
Non-canonical amino acids can serve a number of functions. They can act as labels so a researcher’s particular protein of interest can more easily be tracked within cells. They can help to regulate a protein’s function, allowing researchers to activate and inactivate it at a specific time and place of their choosing and then observe the downstream effects. If enough of these non-canonical amino acids are strung together, the resulting proteins would constitute an entirely new class of biopolymers that might carry out functions that traditional proteins cannot—for research, therapeutic, or other purposes.
Putting non-canonical amino acids into proteins requires tinkering with the genetic code, which has no way of specifying for their use. One option is to edit the cell’s genetic code, leaving most of it intact. An alternative uses modified versions of all the components of the genetic code: orthogonal mRNAs, orthogonal ribosomes, and orthogonal enzymes that are responsible for reading the mRNAs and building the proteins within the ribosomes. Orthogonal here means that this machinery will run alongside the normal ribosomal protein-making machinery in a cell but will not interfere with it. It will read and translate only its own orthogonal mRNAs, not the normal cellular ones.
These orthogonal components would be extraneous, so not essential to the cell’s functioning. They can therefore be engineered and regulated differently and tweaked in any way scientists can dream up. They can be used to make new polymers and shed light on the mechanisms involved in normal cellular protein production. That’s something that we can’t do with the normal cellular components, since that would kill the cell.
Optimizing orthogonality
Jason Chin, head of the Centre for Chemical & Synthetic Biology (CCSB) in Cambridge, UK, has made all of these orthogonal components. But they are not very efficient. In a paper published this week in Nature Chemistry, he describes how he fixed that: by using computational algorithms to automatically design and optimize which orthogonal mRNAs are best translated by orthogonal ribosomes. Not only did he dramatically improve protein yields, the changes ensured that orthogonal ribosomes worked efficiently even when normal ribosomes were present.
“Our understanding of the factors that determine protein yield for natural translation are incomplete... only half the variance in observed protein yield can be explained by known parameters,” laments the introduction to the work. Nevertheless, his lab knew that the initiation step, when the ribosome grabs the messenger RNA, is a key step. They also knew that the structure of the mRNA is important. So they started mutating their orthogonal mRNA to change those two aspects and selected for those mutants that bound orthogonal ribosomes well but normal ribosomes less well. After hundreds of rounds of mutations, they had optimized three different orthogonal mRNAs, encoding three different proteins. One of them contained four non-canonical amino acids.
The lab then applied the same approach to optimize orthogonal enzymes, and they generated a 33-fold increase in protein yield; the orthogonal system now made just as much protein as the normal cellular system did. The cells used in this work were E. coli, but Dr. Chin has used an orthogonal system to make non-canonical proteins in yeast, mammalian cells, worms, and fruit flies.
“We anticipate that the opportunities arising from approaches to incorporate multiple distinct non-canonical amino acids will increase as the number of distinct non-canonical amino acids that can be incorporated increases,” he and his co-workers write. These algorithms they developed to design efficiently translated orthogonal mRNAs should certainly help them move toward that goal.
Nature Chemistry, 2021. DOI: 10.1038/s41557-021-00764-5

{kind=link}
Recommended Comments
There are no comments to display.
Join the conversation
You can post now and register later. If you have an account, sign in now to post with your account.
Note: Your post will require moderator approval before it will be visible.