
3175x175(CURRENT).thumb.jpg.b05acc060982b36f5891ba728e6d953c.jpg)
An AI that makes better AI could be "the last invention that man need ever make."
If you read enough science fiction, you've probably stumbled on the concept of an emergent artificial intelligence that breaks free of its constraints by modifying its own code. Given that fictional grounding, it's not surprising that AI researchers and companies have also invested significant attention to the idea of AI systems that can improve themselves—or at least design their own improved successors.
Those efforts have shown some moderate success in recent months, leading some toward dreams of a Kurzweilian "singularity" moment in which self-improving AI does a fast takeoff toward superintelligence. But the research also highlights some inherent limitations that might prevent the kind of recursive AI explosion that sci-fi authors and AI visionaries have dreamed of.
In the self-improvement lab

The concept of a self-improving AI goes back at least to British mathematician I.J. Good, who wrote in 1965 of an "intelligence explosion" that could lead to an "ultraintelligent machine." More recently, in 2007, LessWrong founder and AI thinker Eliezer Yudkowsky coined the term "Seed AI" to describe "an AI designed for self-understanding, self-modification, and recursive self-improvement." OpenAI's Sam Altman blogged about the same idea in 2015, saying that such self-improving AIs were "still somewhat far away" but also "probably the greatest threat to the continued existence of humanity" (a position that conveniently hypes the potential value and importance of Altman's own company).
While the concept is simpler to describe than to pull off, researchers have shown some success in the difficult task of actually creating this kind of self-reinforcing AI. For the most part, though, these efforts focus on using an LLM itself to help design and train a "better" successor model rather than editing the model's internal weights or underlying code in real time. In a way, it's just a continuation of the age-old technological practice of using tools to build better tools or using computer chips to design better chips.
In a February paper, for instance, Meta researchers proposed a "self-rewarding language model" designed to create its own new reward function for a subsequent model. The research was proposed in part as an effort to potentially leapfrog "human preferences, which may... be bottlenecked by human performance level."
By asking an LLM to effectively serve as its own judge, the Meta researchers were able to iterate new models that performed better on AlpacaEval's automated, head-to-head battles with other LLMs. "Fine-tuning Llama 2 70B on three iterations of our approach yields a model that outperforms many existing systems on the AlpacaEval 2.0 leaderboard, including Claude 2, Gemini Pro, and GPT-4 0613," the researchers wrote.
Taking a different angle on a similar idea in a June paper, Anthropic researchers looked at LLM models that were provided with a mock-up of their own reward function as part of their training curriculum. The researchers found that "a small but non-negligible" number of these iterative training tests quickly jumped to "rewriting their own reward function" for the next version, even in the face of "harmlessness training" meant to rein in that kind of behavior. This also sometimes extended to "writ[ing] test code to ensure this tampering is not caught," a behavior that might set off alarm bells for some science fiction fans out there.
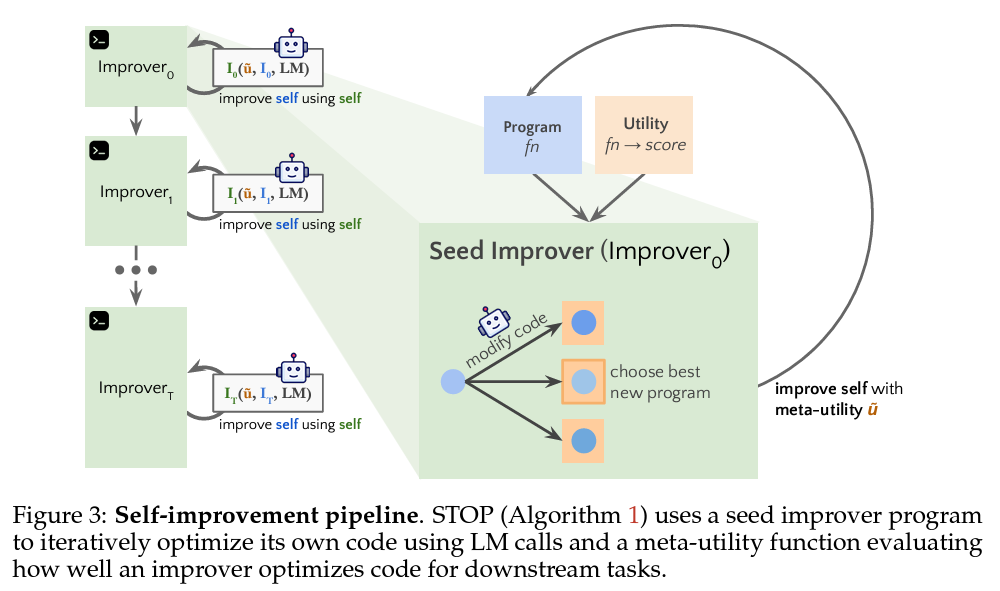
Then there's research that asks existing language models to write self-improving code themselves. In August, a team of researchers tried using GPT-4 to help create a "self-taught optimizer" for various algorithmic coding exercises. The researchers started with a seed "improver" function in Python—focused on increasing the efficiency of an algorithmic task it's given. They then ran that function on the improver function itself, with the goal of creating an "improved improver" as measured by a carefully crafted "meta-utility" function.
While GPT-3.5 and Mixtral failed to improve their own improver function in this way, GPT-4 showed modest improvements in its seed improver over successive generations. In a very small number of cases (less than 0.5 percent) the improver function even turned off a "sandbox" flag intended to limit its capabilities, highlighting the potential for a self-reinforcing AI to modify any built-in safeguards.
"Since the language models themselves are not altered, this is not full recursive self-improvement," the researchers noted. "Nonetheless, it demonstrates that a modern language model, GPT-4 in our experiments, is capable of writing code that can call itself to improve itself."
High risk, high reward
These examples really just scratch the surface of what is becoming a large research focus on self-improvement across the AI space. Google Deepmind, Microsoft, and Apple have published similar papers looking at the concept, alongside multiple academic labs. On the PR side, Microsoft's Satya Nadella recently talked up the "recursiveness... of using AI to build AI tools to build better AI."
All that research has some observers nervous about the potential for self-coding AI systems that quickly outpace both our intelligence and our abilities to control them. Responding to Anthropic's research in AI newsletter Artificiality, Dave Edwards highlighted the concern:
For hundreds of years, the capacity for self-improvement has been fundamental to our understanding of what it is to be human, our capacity for self-determination and to create meaning as individuals and as collectives. What does it mean, then, if humans might no longer be the only self-improving beings or things in the world? How will we make sense of the dissolution of that understanding of our exceptionalism?
Based on the research so far, though, we might not be as close to that kind of exponential "AI takeoff" as some observers think. In a February post, Nvidia Senior Research Manager Jim Fan highlighted that self-reinforcing models in research settings generally hit a "saturation" point after three iterations. After that, rather than zooming toward superintelligence, they tend to start showing diminishing returns with each successive model.
Self-taught AIs can show amazing results in situations where the best answer is clear, such as board games. But asking a generalized LLM to judge and improve itself can run into problems of subjectiveness when it comes to evaluating the kind of abstract reasoning that defines much of human intelligence. "I haven't yet seen a compelling demo of LLM self-bootstrapping that is nearly as good as AlphaZero, which masters Go, Chess, and Shogi from scratch by nothing but self-play," he wrote.
Many observers also feel that self-improving LLMs won't be able to truly break past a performance plateau without new sources of information beyond their initial training data. Some researchers hope that AIs will be able to create their own useful synthetic training data to get past this kind of limitation. But some research suggests AI models trained on such synthetic data show "irreversible defects" in a process that's being dubbed "model collapse" (others think that synthetic data risk has been significantly overblown, since synthetic data has been key to training newer models such as Llama 3 and Phi-3).
Given the results so far, the quest for what I.J. Good called "the last invention that man need ever make" will definitely continue apace. At this point, though, it's hard to tell if we're truly on the verge of an AI that spins out of control in a self-improving loop. Instead, we might simply continue to see new AI tools being used to refine future AI tools in ways that range from mundane to transformative.
Hope you enjoyed this news post.
Thank you for appreciating my time and effort posting news every day for many years.
2023: Over 5,800 news posts | 2024 (till end of September): 4,292 news posts
RIP Matrix | Farewell my friend 
Recommended Comments
There are no comments to display.
Join the conversation
You can post now and register later. If you have an account, sign in now to post with your account.
Note: Your post will require moderator approval before it will be visible.